Uso de Machine Learning para detectar señales cerebrales de tipo P300 generando estímulos visuales y auditivos
Use of Machine Learning to detect P300-type brain signals by generating visual and auditory stimuli
Resumen: La señal P300 es un potencial evocado que se produce en la región occipital del cerebro cuando se presenta un cambio visual o auditivo inesperado a un patrón lumínico o sonoro. Este pulso es comúnmente estudiado en el campo de la biomedicina, usado en recuperación parcial de movilidad de pacientes cuadripléjicos por medio de una pantalla con diferentes comandos, en el que el paciente mueve los ojos hacia el comando que desea, y generando la P300 se realiza el comando deseado. Es a partir de aquí, que se le da uso a modelos de aprendizaje de Machine Learning, siendo Regresión Logística, Árbol de Decisión, Máquina de Soporte Vectorial y K Vecinos Más Cercanos, para reconocer características de señales electroencefalográficas con presencia y ausencia de P300 y se les aplica un aumento de datos mejorando los entrenamientos, para así obtener el análisis de los mejores predicadores de la señal cerebral P300.
Palabras clave: Machine Learning, P300, electroencefalografía, aumento de datos.
Abstract: The P300 signal is an evoked potential that occurs in the occipital region of the brain when an unexpected visual or auditory change to a light or sound pattern is presented. This pulse is commonly studied in the field of biomedicine, used in partial recovery of mobility in quadriplegic patients through a screen with different commands, in which the patient moves his eyes towards the desired command, and generating the P300 is performed. the desired command. It is from here that the Machine Learning models are used, being Logistic Regression, Decision Tree, Support Vector Machine and K Nearest Neighbors, to recognize characteristics of electroencephalographic signals with the presence and absence of P300 and an increase in data is applied to them by improving the training, in order to obtain the analysis of the best predictors of the P300 brain signal.
Keywords: Machine Learning, P300, electroencephalography, data augmentation.
1. INTRODUCCIÓN
La señal electroencefalográfica P300 es un potencial evocado que se produce en el cerebro
, más específicamente en la región occipital
, el cual corresponde a la parte de atrás de la cabeza, cuando se percibe un estímulo visual o auditivo aleatorio
. Esta señal es un pulso de voltaje positivo generado aproximadamente 300 milisegundos después del estímulo (ver Fig. 1), aunque puede encontrarse en rangos de 250 a 400 milisegundos
.
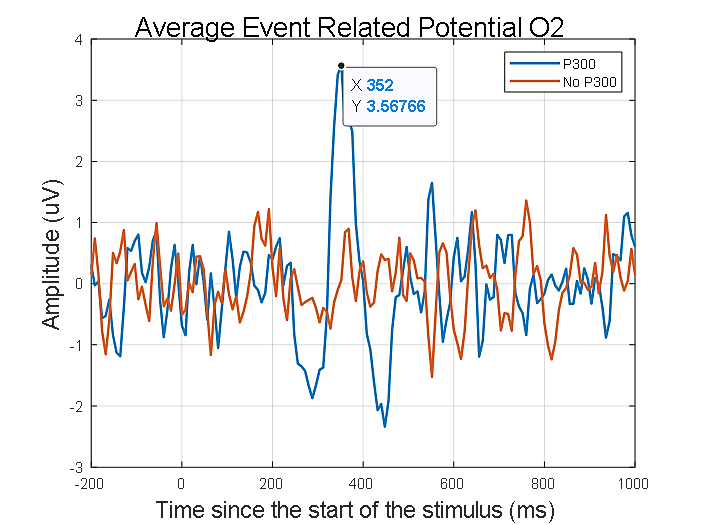
Fig. 1. Comparación entre presencia y ausencia de potencial evocado en el electrodo O2.
Fuente: elaboración propia.
La P300 es una señal electroencefalográfica comúnmente usado en el campo de la biomedicina para la recuperación parcial de movimiento en pacientes parapléjicos o cuadripléjicos
. Estudios que soportan este concepto corresponden a los siguientes:
- Interfaces Cerebro-Computadora (BCI): Se han venido desarrollando BCI’s basadas en la señal P300 para ayudar a personas con discapacidades físicas a comunicarse y controlar dispositivos . Estas aplicaciones van desde el control de sillas de ruedas eléctricas hasta la escritura de texto . Se incluyen estudios como potenciales evocados, con el cual se logran extraer características de las señales EEG luego de haber aplicado etapas de pre-procesamiento y filtrado .
- Algoritmos de Machine Learning: Investigadores han venido aplicando una variedad de algoritmos de Machine Learning, como sistemas SVM, redes neuronales como Deep Learning , y técnicas de procesamiento de señales para detectar y decodificar las señales P300 de manera más precisa y eficiente. Estos estudios inician con la comunicación entre el hardware de los electrodos, con el software que crea los estímulos, al igual que el software que entrelaza las lecturas EEG .
- Aplicaciones Clínicas: Se han explorado aplicaciones clínicas, como la rehabilitación de pacientes con lesiones de médula espinal y la mejora de la calidad de vida de personas con paraplejia y cuadriplejia. Además, se mencionan estudios relacionados con la creación de electrodos no invasivos y con reducción de ruido efectivo .
- Optimización de Estímulos Visuales: Científicos han estado investigando la creación de estímulos visuales efectivos que pudieran desencadenar respuestas P300 confiables, lo que es crucial para la precisión de los sistemas BCI, realizando análisis en datos de series de tiempo, y explicando las dificultades y correcciones a los problemas principales que se producen en la captación de señales EEG .
- Colaboraciones Interdisciplinarias: Por último, investigadores han ejercido su labor en la creación de estímulos visuales efectivos que pudieran desencadenar respuestas P300 confiables, lo que es crucial para la precisión de los sistemas BCI, realizando análisis en datos de series de tiempo, y explicando las dificultades y correcciones a los problemas principales que se producen en la captación de señales EEG .
A partir de estas ideas, se realizó la investigación orientada hacia la predicción de la señal P300 usando modelos de aprendizaje supervisado de Machine Learning
. Esto tiene el fin práctico de poder implementar los modelos más favorables a estudios electroencefalográficos donde circunstancias tales como ruido y alta distancia entre la región de lectura y la región de estudio puedan llegar a usar los modelos de Machine Learning con mayor eficiencia de detección de patrones cerebrales, difíciles de detectar a simple vista, junto con modelos de aprendizaje supervisado eficientes para la detección de patrones cerebrales.Colaboraciones Interdisciplinarias: Por último, investigadores han ejercido su labor en la creación de estímulos visuales efectivos que pudieran desencadenar respuestas P300 confiables, lo que es crucial para la precisión de los sistemas BCI, realizando análisis en datos de series de tiempo, y explicando las dificultades y correcciones a los problemas principales que se producen en la captación de señales EEG
.
Se usó los modelos de Regresión Logística
, Árbol de Decisión
, Máquina de Soporte Vectorial, y K Vecinos más Cercanos
, a los cuales se les sometieron los mismos datasets, se entrenaron los modelos, y cada uno arrojó los datos predichos, calculando con eso el error que presentaban cada uno. La información suministrada a los modelos eran las características extraídas de las señales electroencefalográficas con presencia y ausencia de la P300, con sus respectivas etiquetas, con lo cual se separaron los datos en entrenamiento, validación y pruebas.Colaboraciones Interdisciplinarias: Por último, investigadores han ejercido su labor en la creación de estímulos visuales efectivos que pudieran desencadenar respuestas P300 confiables, lo que es crucial para la precisión de los sistemas BCI, realizando análisis en datos de series de tiempo, y explicando las dificultades y correcciones a los problemas principales que se producen en la captación de señales EEG
.
2. DESARROLLO
Se inició por el ensamblaje del casco que sostendría los electrodos que medirán los voltajes alrededor del cuero cabelludo, localizados entre la región occipital, temporal y central de la cabeza. A través del programa OpenBCI, se captaron las variaciones eléctricas en cada uno de los 16 electrodos (ver Fig. 2), y se transmitieron a través de comunicación LSL, el cual permite enviar tramos de datos, de hasta 3 tramos de diferentes datos de manera simultánea.Colaboraciones Interdisciplinarias: Por último, investigadores han ejercido su labor en la creación de estímulos visuales efectivos que pudieran desencadenar respuestas P300 confiables, lo que es crucial para la precisión de los sistemas BCI, realizando análisis en datos de series de tiempo, y explicando las dificultades y correcciones a los problemas principales que se producen en la captación de señales EEG
.
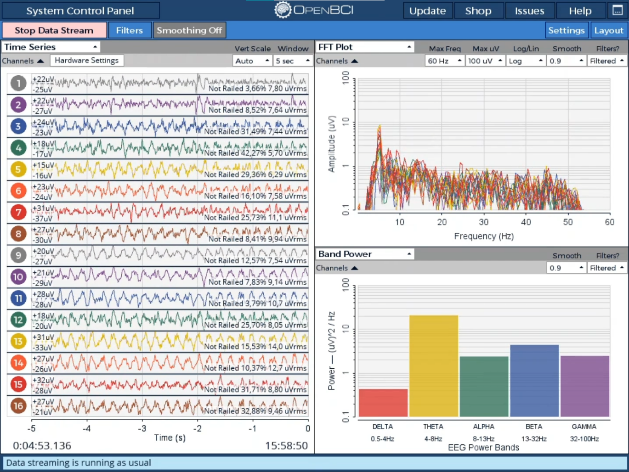
Fig. 2. Interfaz Gráfica de Usuario del programa OpenBCI.
Fuente: elaboración propia.
Una vez se iniciaba la comunicación LSL, la trama de datos se enlazó con los marcadores creados por Psychopy, correspondientes a presencia (1) o ausencia (0) de señal P300, a través de la generación de estímulos visuales y auditivos de forma aleatoria. Teniendo un total de 4 personas en el estudio (ver Fig. 3), cada uno tenía la tarea de observar una pantalla, contar cuántas veces aparecía un cambio repentino de un cuadrado azul constante, y que presionaran un botón en cada aparición del estímulo
. Esto generó los marcadores que indicaron cuándo había aparecido un estímulo aleatorio y cuándo no, proporcionando la información para entrelazarse con las señales electrencefalográficas de OpenBCI.

Fig. 3. Participantes durante las pruebas de generación de P300: 1/A (izquierda), 2/C (Derecha superior), 3/Ma (Derecha central) y 4/Mo (Derecha inferior).
Fuente: elaboración propia.
LabRecorder fue el programa encargado de unificar la información por LSL que llegaba de OpenBCI, con la información LSL que arrojaba Psychopy, creando un último archivo de formato .xdf el cual se abrió con un programa creado en Matlab llamado EEGLab
. Una vez importado a Matlab, se procedió a crear las ventanas que contenían presencia o ausencia de la señal P300, se les extrajo 6 características principales a cada electrodo, los cuales fueron los siguientes:
- El pico máximo de la señal: El valor más alto que alcanzó la ventana de la señal.
- La ubicación del pico máximo: La posición en tiempo del pico de la ventana de la señal.
- El centro de la correlación cruzada: En el momento de realizar la correlación cruzada entre una señal artificial que se asemeja a la señal P300, con la ventana de la señal a extraer características, se obtiene el valor del centro de la correlación, donde entre más alto sea este dato, más parecido a la señal P300 será.
- El área bajo la curva de la correlación cruzada: Si el área se localiza con un valor superior al cero de referencia, indicará que se acerca más a ser una señal P300.
- La potencia promedio de frecuencias de 4 a 5Hz: Se transformó el conjunto de señales del dominio del tiempo al dominio de la frecuencia, y se calculaba el promedio de las potencias en las frecuencias de 4 a 5Hz, y si la potencia promedio es alta, es un indicativo de ser una P300.
- El área bajo la curva de la señal: Se calculó el área bajo la curva de la señal original, el cual fue información útil para los modelos de aprendizaje supervisado.
Todo se guardó en una hoja de cálculo (ver Fig. 4), dando un total de 96 características, por lo que las 6 características se calcularon para cada electrodo de los 16 que se usaron, y una columna adicional por el marcador de presencia o ausencia de P300.
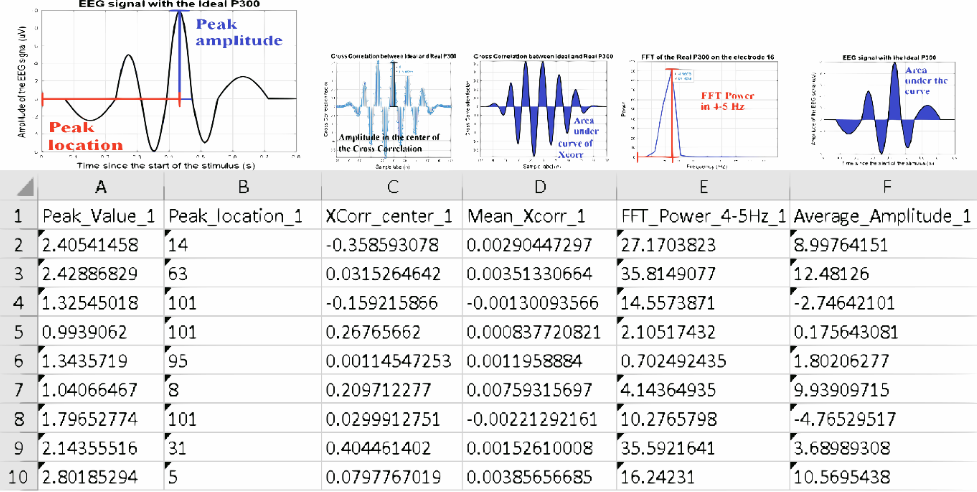
Fig. 4. Dataset con sus correspondientes características extraídas.
Fuente: elaboración propia.
Por último, se generó un aumento de datos para los datasets, manteniendo los valores dentro de los rangos de desviación estándar, con un incremento de 10 veces el dataset original (ver Fig. 5), con el fin de amplificar el entrenamiento de los modelos de Machine Learning.
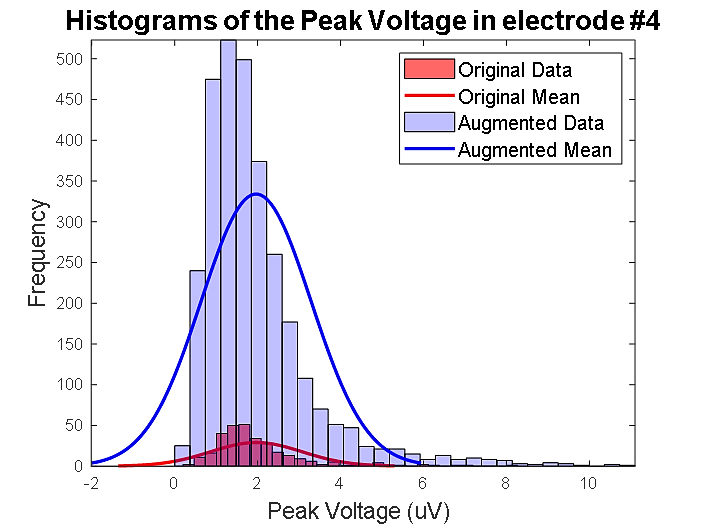
Fig. 5. Histogramas comparando entre datos del dataset original (rojo) con el dataset aumentado (azul).
Fuente: elaboración propia.
Después se procedió a ingresar la información de los datasets a los modelos de entrenamiento, y con esto se validaron y pusieron a prueba cada uno de ellos. Cada uno arrojó los resultados de predicciones satisfactorias y erróneas, los cuales se sometieron a evaluación de métricas, para finalizar con el análisis de estos resultados y establecer cuáles serían los mejores predictores de la señal P300.
3. RESULTADOS
Obtenidas las matrices de confusión de los participantes, involucrando tanto las de validación como las de prueba, para los cuatro tipos de modelos (ver Fig. 6), se observó que las matrices de confusión relacionados a SVM (Máquina de Soporte Vectorial) y KNN (K Vecinos más Cercanos) tienen un más alto número de verdaderos positivos y verdaderos negativos, comparados con los valores de LR (Regresión Logística) y Tree (Árbol de Decisión), los cuales tuvieron muchos más valores en los falsos, tanto positivos como negativos.
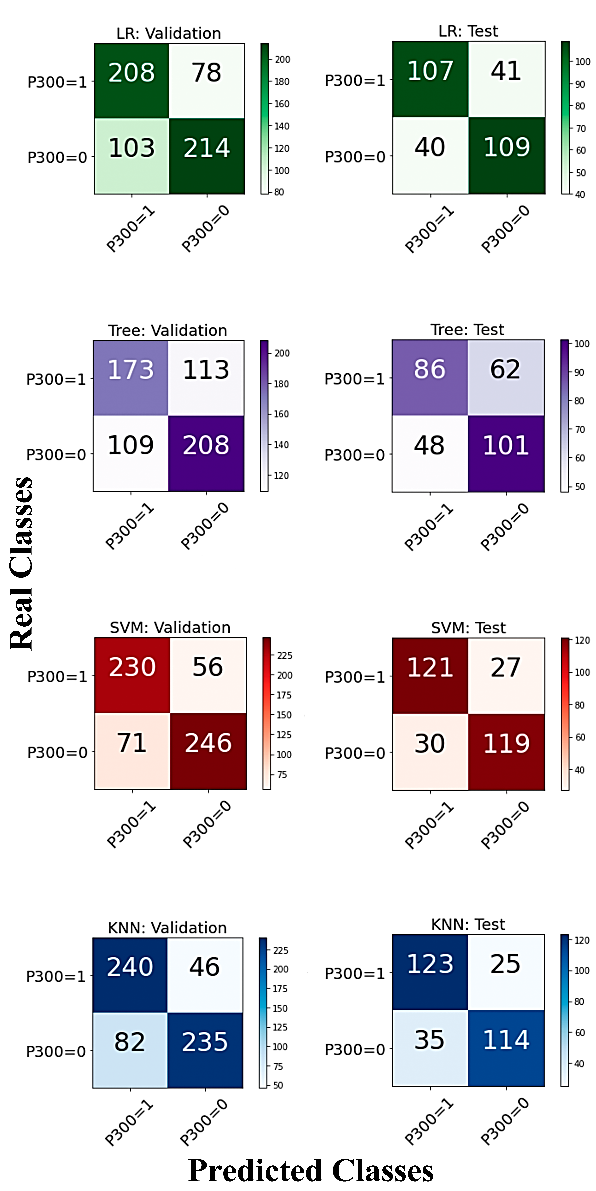
Fig. 6. Matrices de confusión para los datos de validación (izquierda) y los datos de prueba (derecha) con Regresión Logística (Verdes), Árbol de decisión (Morados), Máquina de Soporte Vectorial (Rojos) y K Vecinos más Cercanos (Azules) del participante 1/A.
Fuente: elaboración propia.
El puntaje F1 es un número comprendido entre 0 y 1, el cual indica el porcentaje de aciertos que el modelo realizó cuando ha sido entrenado y se le han presentado nuevos datos para predecir. Un valor cercano a cero indica que no ha sido entrenado satisfactoriamente, por ende, no predice de manera correcta, mientras que un valor cercano a uno indica una mayor precisión en las predicciones que realiza. Este puntaje fue la métrica utilizada para establecer los mejores predictores de la señal P300.
3.1. Datos de Validación
Realizando los cálculos del puntaje F1 de los cuatro participantes, y de ambos datasets por participante, siendo el original y el que tiene el aumento de datos, se obtuvo la siguiente gráfica (ver Fig. 7).
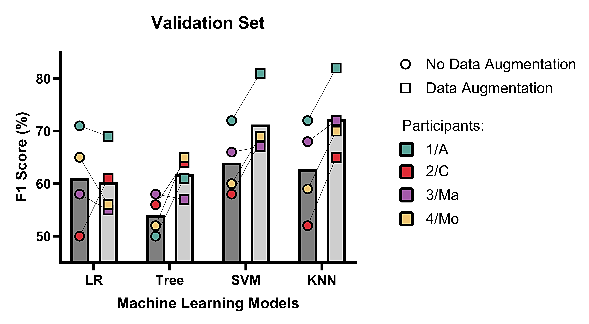
Fig. 7. Porcentaje Puntaje F1 de los cuatro participantes para datos de validación.
Fuente: elaboración propia.
Esto corresponde al 20% del total de datos, ya que el 70% de los mismos son los de entrenamiento.
3.2. Datos de Prueba
Este conjunto correspondió a los datos de pruebas con el 10% del total de los datasets, dando como resultados los siguientes valores (ver Fig. 8).
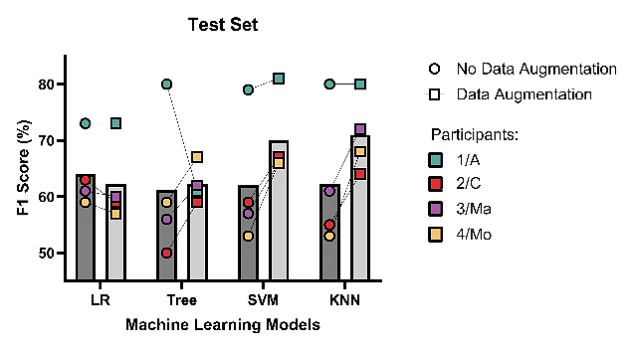
Fig. 8. Porcentaje Puntaje F1 de los cuatro participantes para datos de prueba.
Fuente: elaboración propia.
Esto permitió confirmar que, en ambos casos de validación y de prueba, SVM y KNN fueron aquellos que mejor desempeño presentaron en las predicciones, y mejoraron cuando se les ingresó los datos aumentados, confirmando el beneficio de aumentar los datos para entrenar aún más los modelos de Machine Learning.
4. CONCLUSIONES
Con estos resultados finales, fue posible culminar el proyecto, donde se redactaron las siguientes conclusiones:
- Con ayuda de los programas de OpenBCI, Psychopy y Matlab, fue posible obtener los resultados más favorables en términos de hardware con el casco, y de software con la comunicación de información por medio de LSL. Psychopy resultó ser muy efectivo en términos de establecimiento de marcadores coordinados con la aparición de estímulos visuales y auditivos aleatorios, y con el uso de LabRecorder se ancló de manera satisfactoria las señales EEG con los marcadores, siendo evidencia el potencial evocado visto en los electrodos O1 y O2. Matlab permitió obtener las señales y marcadores para extraerles sus características y crear así el dataset deseado para el estudio, junto con el aumento de datos para mejorar los resultados de predicciones de P300.
- El casco de electroencefalografía tiene un alto rendimiento siempre y cuando se puedan ajustar correctamente los electrodos sobre el cuero cabelludo, ya que se ve afectado por la cantidad de cabello que la persona tenga en el momento de realizar el estudio. De ser posible, para personas de abundante cabello, es recomendable ajustar los electrodos lo más profundo al casco posible, y de tenerse disponibilidad se puede llegar a usar gel conductor que aumente la conductividad de los electrodos sobre la cabeza.
- Las características extraídas de cada electrodo durante el estudio fueron suficientes para entrenar los modelos de aprendizaje supervisado, ya que se aplicó el método de análisis por cada instante en el que aparecía un estímulo, permitiendo realizar predicciones con cada marcador de P300 que iría apareciendo en las señales cerebrales.
- Los modelos de Machine Learning en su mayoría presentaron una mejoría en términos de predicciones de señal P300 en el momento en el que se les generaba un aumento de datos al dataset original, por el hecho de que teniendo más datos para entrenar permitió llegar a acertar con mayor precisión los nuevos datos, información que inicialmente recibía sin las clases.
- Los modelos de aprendizaje supervisado “Máquina de Soporte Vectorial” y “K Vecinos más Cercanos” resultaron ser los mejores predictores de la aparición de la señal P300 en este estudio, el cual se vio menos afectado por circunstancias como ruido, mientras se vio más favorecido por el aumento de datos.
RECONOCIMIENTO
A los participantes que colaboraron para las tomas de datos del estudio.
Y a las instituciones que hicieron partícipe de este proyecto, colaborando con la infraestructura y los elementos necesarios para la implementación y el desarrollo de la presente investigación.
REFERENCIAS
[1] B. Miner, Y. Pan, C. Burzynski, L. Iannone, M. Knauert, T. Gill and H. Yaggi, "0726 Agreement Between an Electroencephalography-Measuring Headband and Polysomnography in Older Adults with Sleep Disturbances," in Sleep, Oxford Academic, 2023, pp. A319-A320.
[2] O. A. Broggi Angulo, D. G. Koc Gonzáles y P. C. Martinez Esteban, «Guía de procedimiento de electroencefalografía y videoelectroencefalografía,» Ministerio de Salud de la República del Perú, San Borja, 2022.
[3] Y. Zhang, H. Xu, Y. Zhao, L. Zhang y Y. Zhang, «Application of the P300 potential in cognitive impairment assessments after transient ischemic attack or minor stroke,» Neurological Research, vol. 43, nº 4, pp. 336-341, 2021.
[4] J. M. Macías Macías, J. A. Ramirez Quintana, J. S. A. Méndez Aguirre, M. I. Chacón Murgia y A. D. Corral Sáenz, «Procesamiento Embebido de P300 Basado en Red Neuronal Convolucional para Interfaz Cerebro-Computadora Ubicua,» ReCIBE. Revista electrónica de Computación, Informática, Biomédica y Electrónica, vol. 9, núm. 2, pp. 1-24, 2020.
[5] «Electroencefalografía (EEG),» 2018. [En línea]. Available: https://brainsigns.com/es/science/s2/technologies/eeg.
[6] S. Silva Pereira, E. Ekin Özer and N. Sebastian-Galles, "Complexity of STG signals and linguistic rhythm: a methodological study for EEG data," Cerebral Cortex, vol. 34, no. 2, 2024.
[7] L. E. Morillo, «ANÁLISIS VISUAL DEL ELECTROENCEFALOGRAMA,» pp. 145-153.
[8] C. F. Blanco Díaz y A. F. Ruiz Olaya, «Caracterización de señales de EEG relacionadas a potenciales evocados visuales en estado estacionario,» Ontare, pp. 18-20, 2019.
[9] R. Chandra Poonia, V. Singh y S. Ranjan Nayak, Deep Learning for Sustainable Agriculture, A volume in Cognitive Data Science in Sustainable Computing, India: Elsevier, 2022.
[10] M. Razavi, V. Janfaza, T. Yamauchi, A. Leontyev, S. Longmire-Monford and J. Orr, "OpenSync: An opensource platform for synchronizing multiple measures in neuroscience experiments," pp. 3-7, 2021.
[11] T. Mo, W. Huang, W. Sun, Y. Hu, L. Mcdonald, Z. Hu, L. Chen, J. Liao, B. Hermann, V. Prabhakaran y H. Zeng, «Activation Map Reveals Language Impairment in Children with Benign Epilepsy with Centrotemporal Spikes (BECTS),» Neuropsychiatric Disease and Treatment, vol. 19, p. 1949–1957, 2023.
[12] C. Biarnés Rabella, «Diseño, caracterización y evaluación de electrodos capacitivos para la medida de ECG y EEG,» Universitat Politécnica de Catalunya, pp. 12-15, 2018.
[13] F. Wu, M. Gong, J. Ji, G. Peng, L. Yao, Y. Li and W. Zeng, "Interval and subinterval perturbation finite element-boundary element method for low-frequency uncertain analysis of structural-acoustic systems," Journal of Sound and Vibration, vol. 462, no. 114939, 2019.
[14] L. Bianchi, A. Antonietti, G. Bajwa, R. Ferrante, M. Mahmud y P. & Balachandran, «A functional BCI model by the IEEE P2731 working group: data storage and sharing,» Brain-Computer Interfaces, vol. 8, nº 3, p. 108–116, 2021.
[15] S. Gannouni, A. Aledaily, K. Belwafi and H. Aboalsamh, "Emotion detection using electroencephalography signals and a zero time windowing based epoch estimation and relevant electrode identifcation," Nature Portfolio, pp. 5-7, 2021.
[16] I. M. Hojas, «Regresión Logística en Python,» [En línea]. Available: https://www.statdeveloper.com/regresion-logistica-en-python/.
[17] R. Romo, «Árboles de Decisión / Decision Trees con python,» [En línea]. Available: https://rubenjromo.com/decision-trees/.
[18] L. Gonzales, «K Vecinos más Cercanos – Teoría,» 19 Julio 2019. [En línea]. Available: https://aprendeia.com/algoritmo-k-vecinos-mas-cercanos-teoria-machine-learning/.
[19] J. G. J. R. S. S. M. M. H. R. S. H. K. E. &. L. J. K. Peirce, «PsychoPy2: Experiments in behavior made easy.,» 2019. [En línea]. Available: https://doi.org/10.3758/s13428-018-01193-y.
[20] Z. Zhang, X. Liang, W. Qin, S. Yu and Y. Xie, "matFR: a MATLAB toolbox for feature ranking," Bioinformatics, vol. 36, no. 19, p. 4968–4969, 2020.
 1,
PhD(c). Camilo Ernesto Pardo Beainy
1,
PhD(c). Camilo Ernesto Pardo Beainy