Sistema tutor inteligente basado en la personalización del aprendizaje para la enseñanza de protocolos de atención en salud
Intelligent tutoring system based on personalized learning for teaching health care protocols
Resumen: La personalización del aprendizaje es un proceso que organiza los contenidos del sistema considerando las características y desempeño de los usuarios utilizando Inteligencia Artificial. Este artículo presenta el diseño y evaluación de un Sistema Tutor Inteligente para la personalización del aprendizaje a través de estrategias pedagógicas basadas en Razonamiento Basado en Casos sobre protocolos de atención para sífilis gestacional y congénita. La metodología fue cuasiexperimental con dos grupos, experimental y control. La muestra estuvo conformada por 68 estudiantes. El grupo experimental utilizó el STI, mientras que el grupo control recibió la formación a través de clases magistrales. El grupo que utilizó el STI obtuvo un mejor logro de aprendizaje frente al otro grupo que aprendió tradicionalmente este tema. Estos resultados podrían sugerir que el uso de aplicaciones de este tipo, facilitaría la creación de nuevos escenarios que permitan un aprendizaje significativo considerando las características y necesidades de los estudiantes.
Palabras clave: Educación para la salud, Estrategia pedagógica, Personalización del aprendizaje, Razonamiento basado en casos, Sistema tutor inteligente.
Abstract: Personalization of learning is a process that organizes system contents considering user characteristics and performance using Artificial Intelligence. This article aims to present the design and evaluation of an Intelligent Tutoring System (ITS) for personalized learning through pedagogical strategies based on Case-Based Reasoning about care protocols for gestational and congenital syphilis. The methodology used in this research was quasi-experimental with two groups, experimental and control. The sample consisted of 68 students. The experimental group was the only one that used the ITS, while the control group received training through lectures. The group that used the ITS obtained better learning achievement than the other group that traditionally learned this topic. These results could suggest that the use of this type of applications, in health education, would facilitate the creation of new learning scenarios that enable meaningful learning considering the characteristics and needs of students.
Keywords: Health Education, Pedagogical Strategy, Personalized Learning, Case-Based Reasoning, Intelligent Tutoring System.
1. INTRODUCCIÓN
El proceso de personalización del aprendizaje se ha convertido en los últimos años en una característica clave en el desarrollo de Sistemas inteligentes para la educación
–
, permitiendo organizar los contenidos del sistema de acuerdo a las necesidades individuales del usuario y su rendimiento por medio de técnicas de Inteligencia Artificial (IA)
,teniendo en cuenta los objetivos del curso y las estrategias implementadas por los docentes
,
. Estas técnicas adaptan el contenido de acuerdo con las individualidades del estudiante decidiendo los recursos de aprendizaje más adecuados desde diferentes representaciones alternativas emulando las estrategias de adaptación comúnmente asociadas a expertos en diseño instruccional
–
. Cuando el proceso de adaptación del aprendizaje se realiza de esta forma, el sistema lleva a cabo, por lo general, un proceso de personalización adaptativa de estrategias pedagógicas
,
,
,
. En Sistemas Tutores Inteligentes (ITS por sus siglas en inglés) una estrategia pedagógica es un plan instruccional que secuencia y organiza el contenido de instrucción teniendo en cuenta: actividades de aprendizaje, forma de presentación, perfil del estudiante, ritmo de aprendizaje e interacción con el sistema
,
. El proceso de personalización de estrategias pedagógicas en ITS puede realizarse desde diferentes enfoques
. El enfoque más común ejecuta la personalización desde el uso de estereotipos o perfiles de los alumnos
,
. Este enfoque agrupa a los estudiantes desde su historial de rendimiento e información general (e.g. estilos de aprendizaje). Este agrupamiento depende del monitoreo que el sistema realiza de la interacción del estudiante con los recursos (puntaje de valoración, frecuencia de uso, etc.) y el puntaje obtenido en evaluaciones parciales y finales, reflejándose en términos de casos exitosos y no exitosos, utilizados por el sistema cada vez que otros estudiantes hacen uso de él
. Por esta razón, la técnica más utilizada en este tipo de personalización de estrategias pedagógicas es el Razonamiento Basado en Casos (CBR por sus siglas en inglés)
,
.
Varios autores han propuesto numerosos estudios sobre la personalización del aprendizaje en STI
,
. Algunos de ellos han realizado este proceso de personalización del aprendizaje desde estrategias pedagógicas
,
,
, haciendo uso de diferentes técnicas de IA y desde diferentes dominios de conocimiento
,
,
. Aunque otros autores han desarrollado ITS para generar procesos de aprendizaje que tengan en cuenta las características del usuario en educación para la salud
,
–
,
,
–
y otros han creado sistemas inteligentes para la enseñanza de diversas enfermedades
,
,
,
, ninguno de ellos ha desarrollado ITS para el aprendizaje de protocolos de atención de sífilis gestacional y congénita, utilizando procesos de personalización adaptativa de estrategias pedagógicas por medio de CBR.
En el departamento de Córdoba-Colombia se presentan altos índices de contagio de sífilis gestacional y congénita
. Además, en el programa de Enfermería de la Universidad de Córdoba, los estudiantes presentan bajos niveles de aprendizaje en los protocolos de atención de esta enfermedad
, la cual es infección considerada un problema de salud pública
. Por lo anterior, el objetivo de este artículo es presentar el diseño y evaluación de un STI de personalización del aprendizaje por medio de estrategias pedagógicas basado en CBR acerca de protocolos de atención de sífilis gestacional y congénita en estudiantes del programa de Enfermería de la Universidad de Córdoba, Colombia. Este artículo se enmarca en el contexto actual de la educación para la salud, donde el desarrollo de sistemas inteligentes personalizados y adaptativos que tengan en cuenta las necesidades e intereses del estudiante se conciben como un desafío apremiante
.
Este artículo se encuentra estructurado de la siguiente manera: primero, se presenta el modelo de ITS para la personalización del aprendizaje, luego, la metodología implementada en este estudio, tercero, se describen los resultados y finalmente, las conclusiones, agradecimientos y referencias.
2. ITS PARA LA PERSONALIZACIÓN DEL APRENDIZAJE EN SÍFILIS GESTACIONAL Y CONGÉNITA
Un ITS es un sistema computacional que ofrece instrucción mediante técnicas de IA orientadas a experiencias de aprendizaje granular
,
, facilitando la adaptabilidad del aprendizaje desde las necesidades específicas o el nivel de conocimiento de los estudiantes. Un ITS se estructura en cuatro componentes básicos
, un módulo experto, módulo estudiante, módulo tutor e interfaz de usuario
-
. Debido que el ITS busca ofrecer instrucción personalizada
,
, su módulo principal es el módulo tutor
, también conocido en la literatura como planificador instruccional
. Los objetivos de aprendizaje y las estrategias pedagógicas que guían el proceso de aprendizaje del estudiante
están alojadas en el modelo pedagógico del módulo tutor. Este modelo pedagógico determina la forma como el ITS adapta sus estrategias pedagógicas en forma de planes instruccionales
,
,
. Estos planes comprenden las estrategias desarrolladas por un diseñador instruccional para lograr objetivos de aprendizaje en los estudiantes a través de recursos de aprendizaje individual
.
El logro de estos objetivos en ITS se alcanza a través de lecciones de aprendizaje que comprenden las estrategias pedagógicas que a su vez son herramientas configurables por el proceso de personalización del sistema. Para esto, cada lección se compone de recursos educativos que tienen en cuenta las características del estudiante, los objetivos pedagógicos y el contexto de aprendizaje
,
. Por lo anterior, el proceso de personalización de estrategias pedagógicas en ITS es muy complejo
,
, para lo que es necesario utilizar algoritmos inteligentes que organicen los recursos de aprendizaje de acuerdo a las necesidades individuales de los estudiantes y su rendimiento
,
. De acuerdo a
estos algoritmos permiten desarrollar el proceso de personalización de estrategias pedagógicas en ITS desde un enfoque granular, donde los estudiantes son agrupados de acuerdo a sus características específicas y datos de interacción para ofrecer una experiencia de aprendizaje cada vez más personalizada. Entre los algoritmos más utilizados para este tipo de personalización se encuentra CBR. Esta técnica de IA intenta resolver problemas utilizando el conocimiento de experiencias previas en casos similares. acontecimientos similares (Casos).
En la presente investigación se ha desarrollado un ITS sobre protocolos de atención de sífilis gestacional y congénita que personaliza estrategias pedagógicas utilizando CBR, el cual será descrito a continuación. El ITS fundamentó sus arquitectura en el metamodelo Metagogic el cual fue diseñado para orientar el desarrollo de ITS con características de personalización adaptativa de estrategias pedagógicas [4, p.] En la Fig. 1 se representa la relación entre los paquetes que configuran el ITS desarrollado en esta investigación. En este metamodelo se afirma que en el paquete Planner (módulo tutor) del STI se alojan los algoritmos de personalización del sistema.
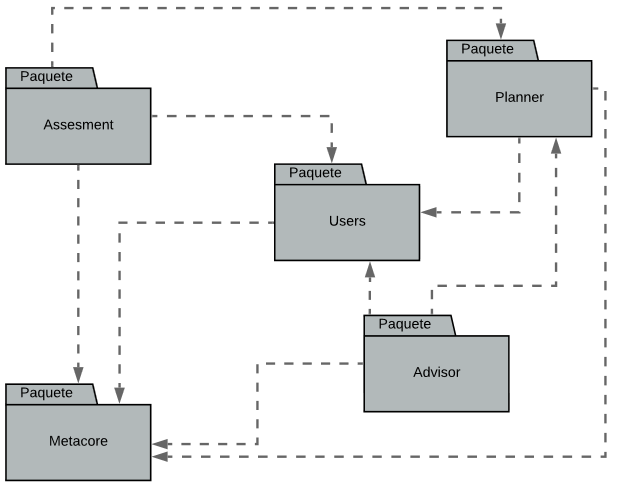
Fig. 1. Paquetes del Metamodelo Metagogic.
Fuente: elaboración propia.
La Fig. 2 ejemplifica las clases que componen el paquete Planner del ITS desarrollado en este estudio. Este paquete selecciona la Estrategia Pedagógica más adecuada para cada estudiante. Una Estrategia Pedagógica es un plan compuesto por un Contexto (datos generales sobre Estudiante, Curso, Lección), un Enfoque pedagógico (Teorías de Aprendizaje y Métodos de Enseñanza) y una Actividad de Aprendizaje (contenido de una Lección que define las Tácticas Pedagógicas y los Recursos de Aprendizaje).
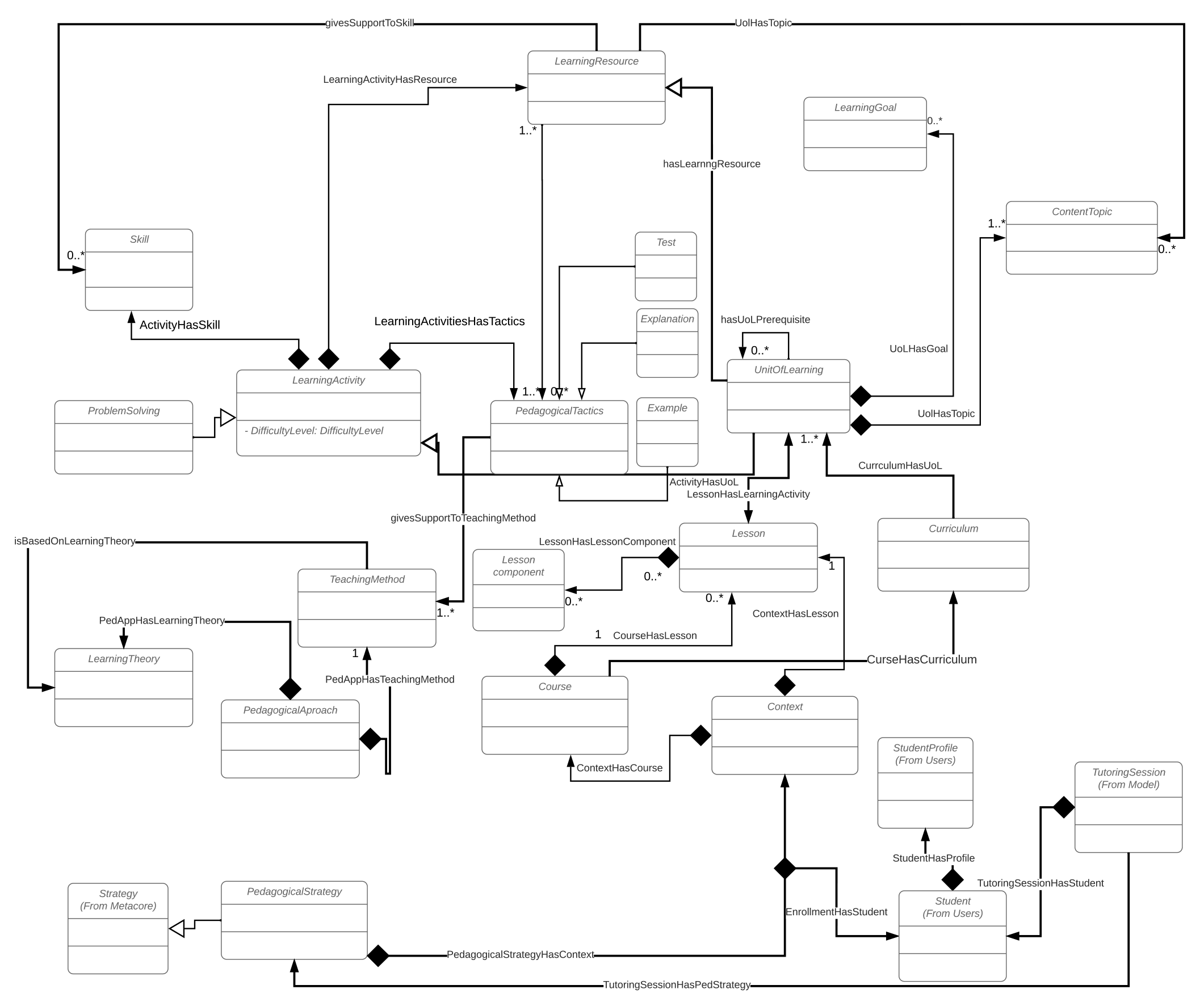
Fig. 2. Estructura del paquete Planner del ITS.
Fuente: elaboración propia.
En el ITS las Tácticas Pedagógicas se definen como componentes de una lección (Introducción, definición, descripción, ejemplo, actividad y evaluación) y estas requieren Recursos de Aprendizaje para desarrollarse. Esta clase Estrategia Pedagógica también aloja el algoritmo CBR encargado de seleccionarlas. A continuación, en la tabla 1 se describe el flujo de control básico de alto nivel de este algoritmo.
Tabla 1: Algoritmo CBR para la selección de estrategias pedagógicas en Metagogic.
|
Código |
Comentario |
| 1: |
procedure CBR (ε) |
|
| 2: |
γn ← μ.new() |
◃nuevo caso temporal |
| 3: |
ρ(ε, γn) |
◃1er paso del ciclo CBR |
| 4: |
γn ← α(γn, υ.pref.tr, υ.pref.er) |
◃2o paso del ciclo CBR |
| 5: |
σ(κ(γn)) |
◃3er y 4o paso de CBR |
| 6: |
procedure ρ(ε, γt) |
|
| 7: |
for i ← 0 to μ(EOF) |
◃Búsqueda en Memoria |
| 8: |
if γt[i].ε = ε and γt[i].pe = max(μ.pe) then γt ← γt[i] |
|
| 9: |
Planner(γt) |
◃Ejecución del caso |
| 10: |
procedure α(γt, tr, er) |
|
| 11: |
γt.tr ← tr |
◃Tiempo del caso |
| 12: |
γt.er ← er |
◃Evaluación del caso |
| 13: |
return (γt) |
|
| 14: |
procedure κ(γt) |
|
| 15: |
if γt.tr ≥ min(μ.tr) and γt.er > 3 then |
|
| 16: |
γt.state ← successful |
◃Caso exitoso |
| 17: |
else |
|
| 18: |
γt.state ← unsuccessful |
◃Caso no exitoso |
| 19: |
return (γt) |
|
| 20: |
procedure σ(γt) |
|
| 21: |
μ.modify(γt) |
◃Guardar el caso |
Fuente: elaboración propia
El algoritmo crea un nuevo caso γ
n (línea 2) e inicia el ciclo de pasos del proceso CBR (línea 3) con el paso de Recuperación ρ, el cual requiere el estilo del aprendizaje ε del estudiante y el caso creado como datos de entrada. Este paso realiza una búsqueda en la memoria de casos μ (línea 7) de acuerdo al estilo de aprendizaje del caso y escogiendo el caso más parecido con el mayor peso euclidiano p
e almacenado en la memoria de casos (utilizando el algoritmo de k-vecinos), para luego ejecutarlo en la interfaz por medio del paquete Planner. Una vez ejecutado, el paso de adaptación α (línea 4) asigna el tiempo de uso t
r que el estudiante hace del caso y la evaluación e
r del mismo, para luego devolverlo con estas nuevas asignaciones (línea 13). El paso de verificación κ corrobora las condiciones para catalogar un caso como exitoso o no exitoso (línea 15). Para que el caso sea considerado exitoso, su tiempo de interacción con el usuario debe ser el mínimo tiempo dispuesto en memoria y su evaluación debe ser mayor a 3 puntos. Por último, el caso es almacenado en la memoria de casos en el paso de almacenamiento σ (línea 5).
El Enfoque Pedagógico se configura desde el contexto de la estrategia pedagógica, por lo que es posible tener para cada estudiante un enfoque pedagógico individualizado. Muchos estudios han usado Metagogic para el desarrollo de ITS con personalización adaptativa de estrategias pedagógicas
,
,
,
,
. Para ello, se han utilizado diferentes técnicas de AI: Razonamiento basado en reglas
, Autonomía dirigida a objetivos
,
, algoritmos cognitivos
, entre otros. Sin embargo, ninguno de estos ha implementado CBR como mecanismo de razonamiento del paquete Planner del sistema. La arquitectura del ITS ofrece rutas de aprendizaje personalizado en tiempo real, basado en el modelo de estilo de aprendizaje de Felder-Silverman
, el cambio dinámico y progresivo en el comportamiento del alumno durante el proceso de aprendizaje y las experiencias de aprendizaje exitosas anteriores de otros alumnos. Estas características son utilizadas para aprovechar al máximo el comportamiento del algoritmo CBR, el cual ha sido seleccionado debido a su capacidad inherente de mantener el conocimiento previo en su repositorio y reutilizar el conocimiento pasado mantenido. Además, Metagogic posee una estructura de datos que facilita el comportamiento de algoritmos CBR para el perfilamiento del usuario (paquete Usuario), clasificación por estilos de aprendizaje (Módulo estilos de aprendizaje y progreso de aprendizaje), monitoreo y seguimiento de los estudiantes (módulo Traza de rendimiento y preferencias), tiempo y evaluación de recursos (módulo recurso de aprendizaje en el paquete Planner), selección de estrategias pedagógicas (Módulo de estrategias pedagógicas en el paquete Planner) y representación de estrategias pedagógicas como planes instruccionales (Módulo Plan en el paquete Metacore). Todas estas ventajas se evidencian en los resultados empíricos de este estudio.
Los lenguajes de programación utilizados para el desarrollo del STI fueron: JavaScript y Python. MongoDB se utilizó como gestor de base de datos y VueJS fue el framework utilizado para el diseño de la interfaz. El STI se encuentra disponible en la siguiente dirección web (
https://fichasyprotocolosensalud.com/)
3. METODOLOGÍA
La presente investigación siguió un diseño cuasiexperimental con dos grupos (experimental y control). A los dos grupos se les implementó un Pre-test y Post-test para identificar el nivel de aprendizaje
. Los dos grupos se conformaron en forma aleatoria, para este caso el grupo de control estuvo conformado por 36 estudiantes y el grupo experimental por 32 estudiantes. Estos grupos poseían características similares y estuvieron bajo la responsabilidad del docente encargado de la asignatura que se escogió para el estudio. El grupo experimental fue el único grupo que utilizó el STI, mientras que el grupo de control desarrolló los contenidos de manera tradicional, orientados por el docente de la asignatura. La experiencia se llevó a cabo durante 30 días con sesiones de dos horas diarias de forma sincrónica y los estudiantes podían acceder al sistema de forma asincrónica libremente en otros momentos. Este estudio se aplicó con estudiantes del programa de Enfermería de la Universidad de Córdoba, Colombia matriculados en la asignatura Materno infantil, 68 estudiantes, 57 mujeres y 11 hombres cuyas edades estaban comprendidas entre 21 y 28 años.
Para el desarrollo del estudio se determinaron cuatro fases que son descritas a continuación. La primera fase consistió en un proceso de familiarización de los estudiantes con la investigación, presentando los objetivos y actividades de la misma. Adicionalmente, se procedió a firmar un consentimiento informado por parte de los estudiantes que desearon participar en el estudio. Para finalizar esta fase, una sesión de interacción inicial con el STI fue desarrollada. La segunda fase comprendió la aplicación del Pre-Test, el cual fue implementado a los dos grupos de estudiantes de la investigación, durante un tiempo de 30 minutos. Cabe destacar que este instrumento fue un cuestionario conformado por 10 preguntas de selección múltiple con única respuesta. Este instrumento fue previamente desarrollado y validado en el marco de la investigación. A continuación se presentan los resultados del proceso de validación. Se aplicó el coeficiente de Alfa de Cronbach obteniendo un resultado de 0,773, lo que evidenció la fuerte relación entre las preguntas y el alto nivel de fiabilidad del instrumento. Además, se realizó la adecuación de esfericidad con las medidas de KMO (0,652) y la prueba de Bartlett (82,54 con 45 grados de libertad y asociado a un valor de significancia inferior a 0,001). Lo anterior verifica un buen nivel de relación entre las variables del instrumento. La tercera fase metodológica del estudio fue la aplicación del STI al grupo experimental. Para esto, se habilitó diariamente una sala de informática compuesta por 35 computadores en un lapso de dos horas. Los estudiantes que no alcanzaban a terminar la unidad del curso lo podían continuar desarrollando fuera de la sesión de tutoría. En cuanto al grupo de control, el mismo docente continuó el desarrollo temático de forma habitual. La última fase de la investigación fue la aplicación del Post-test, el cual consistió en un cuestionario de diez preguntas de selección múltiple similares a las planteadas en el Pre-test. Este instrumento también fue desarrollado y validado previamente en el marco de la investigación. Los resultados de su validación son: el coeficiente de Alfa de Cronbach con un valor de 0,796, las medidas de KMO (0,622) y la prueba de Bartlett (112,01 con 45 grados de libertad y asociado a un valor de significancia inferior a 0,000).
4. RESULTADOS
Con el fin de realizar un análisis detallado de los resultados obtenidos por la aplicación de los instrumentos, se implementó una prueba ANOVA de un solo factor con sus respectivos análisis de cumplimiento de supuestos y las respectivas comparaciones múltiples de las calificaciones de cada test con una prueba de Tukey. Esto último con la intención de conocer si el Post-Test presentaba una mejor calificación que el Pre-test y por ende un mejor rendimiento de los estudiantes después de utilizar el STI.
4.1. Prueba de Diferencia de Promedios
Para el análisis comparativo se realizaron algunos estadísticos descriptivos para los estudiantes de la muestra, utilizando las notas obtenidas de los instrumentos de Pre-Test y Post-Test, así como los intervalos de confianza para la calificación media de cada test.
Tabla 2: Clasificación de la discriminación para los ítems del pre y post-test en los grupos de control y experimental.
| Test |
Grupo |
n |
Media |
Des. Est. |
Coef. Var. |
Intervalo de confianza |
| Pre-Test |
Control |
36 |
6,6 |
1,2 |
17,1% |
6,1 - 6,9 |
|
Experimental |
32 |
6,3 |
1,4 |
21,5% |
5,8 - 6,8 |
| Post-Test |
Control |
36 |
7,9 |
1,1 |
12,2% |
7,7 - 8,3 |
|
Experimental |
32 |
9,2 |
0,9 |
8,4% |
8,9 - 9,5 |
Fuente: elaboración propia
En la tabla 2 se observa que mientras los promedios e intervalos de confianza para el grupo de control y experimental tienden a ser similares durante el Pre-Test, se observa un aumento en la nota promedio al momento de realizar el Post-Test. Además, se evidencia una diferencia entre el promedio del resultado de ambos grupos resaltando un mejor rendimiento para el grupo experimental.
4.2. Análisis de Varianza
Para confirmar el comportamiento anteriormente descrito, se realizó un análisis de varianza entre los resultados del grupo control y experimental con respecto al Post-Test que se realizaron bajo condiciones controladas. Para ello, se definió un diseño completamente al azar y se obtiene el siguiente resultado dadas las hipótesis:
- H_0: No hay diferencias significativas entre las medias de los diferentes grupos.
- H_1: Al menos un par de medias son significativamente distintas la una de la otra.
De esta manera, se aplica una prueba ANOVA de un solo factor, obteniéndose como resultado un p-valor no significativo (p-valor>0,05) para el promedio de la nota promedio de los estudiantes al momento de realizar el Pre-Test y conformar los grupos de control y experimental, lo cual permite establecer la no existencia de una diferencia estadística entre los valores promedios de las calificaciones de los test realizados por los estudiantes que conforman cada grupo de estudio (ver Fig. 3).
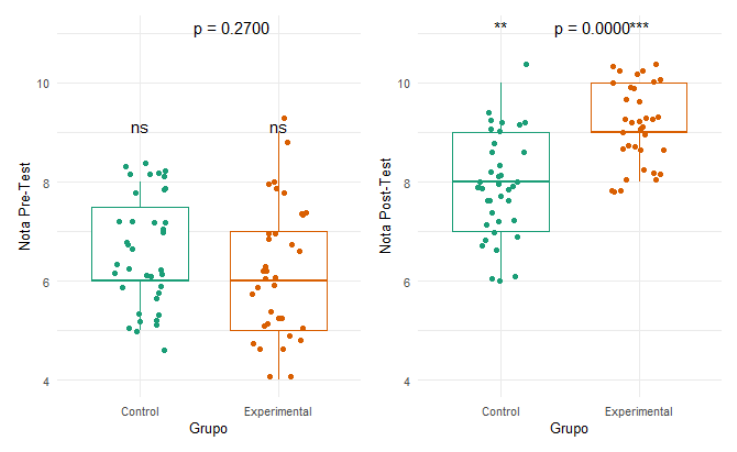
Fig. 3. Análisis de varianza para las calificaciones de los test en cada uno de los grupos.
Fuente: elaboración propia.
Observando la Fig. 3 en su parte derecha, se confirma el p-valor de rechazo (p-valor < 0.05) de la hipótesis nula para la calificación final del Post-Test, que conlleva a rechazarla y a afirmar con un 95% de confianza que en promedio la calificación del Post-Test es mayor en alguno de los grupos de estudio, control o experimental. De igual forma, al realizar el test de Kruskal-Wallis como una alternativa no paramétrica para no ajustar los datos necesariamente a una distribución normal, se encuentra un p-valor de 9.396e-07 que es inferior a 0.05 y se confirma la significancia de la diferencia en los dos grupos.
Por lo anterior, fue necesario realizar comparaciones múltiples de las calificaciones aplicando la prueba de Tukey. Esto con la intención de conocer cuál era el test con mejor resultado, si antes o después de aplicar el STI.
Prueba de comparaciones múltiples de Tukey (Contraste Post-HOC): Cómo se rechazó la H_0 de igualdad de medias en el análisis de varianza (ANOVA), se indagó difieren estos resultados a través de la prueba de comparaciones múltiples con el test de Tukey, usando las siguientes hipótesis.
Para t tratamientos, se tienen en total t(t-1)/2 comparaciones con estadístico de prueba para cada una de las hipótesis de la correspondiente diferencia en valor absoluto entre sus medias muestrales. De esta manera se encontró que son diferentes y que en promedio las calificaciones del Post-Test para los estudiantes seleccionados son superiores a las del Pre-Test con un nivel de confianza del 95%, tal como puede observarse en la Fig. 4.
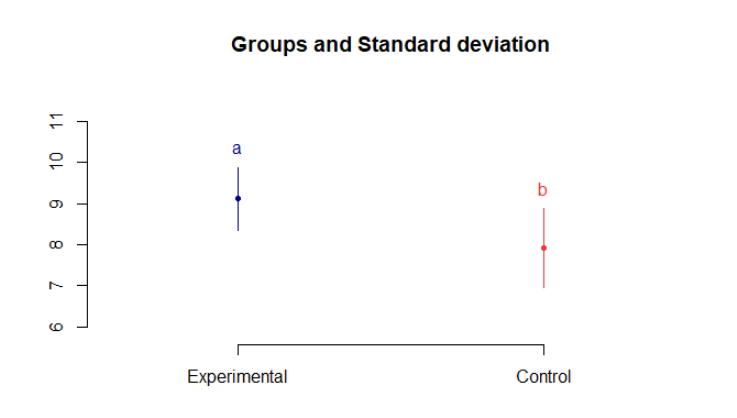
Fig. 4. Comparación de los valores promedios de los grupos de control y experimental de las calificaciones para el Post-Test aplicando la prueba de Tukey.
Fuente: elaboración propia.
De la figura 4 se puede inferir que, teniendo en cuenta las calificaciones de los test de cada grupo, el Post-Test para el grupo experimental tiene una menor variabilidad como se observó en el análisis descriptivo y que su calificación difiere y es mayor a la del Post-Test realizado por el grupo de control.
Cabe resaltar que, aunque ambos promedios de puntaje aumentaron para el Post-Test en cada grupo, para el grupo experimental fue mayor y además estadísticamente difiere al del grupo control. Además, como medida no paramétrica para confirmar que estos dos grupos difieren se utiliza el método de Holm teniendo un p-valor de 9.7e-07 confirmando así, la diferencia significativa.
4.3. Validación de los Supuestos para el Análisis de Varianza
La verificación de los supuestos del análisis de varianza garantiza que el modelo empleado sea adecuado para el análisis.
4.3.1. Distribución normal de los residuos
Este supuesto establece que los residuos deben estar normalmente distribuidos e_i~N(0,1). A continuación, se presenta una curva de densidad observada de las frecuencias de los residuos y el gráfico de probabilidad normal, considerando que la curva de densidad observada se asemeja a la campana de Gauss, y que, en el gráfico de probabilidad normal, los cuantiles observados de los residuos de la variable de interés se aproximan a la línea central que representa los cuantiles de una distribución normal teórica por lo que no existen indicios de incumplimiento del supuesto de normalidad (ver Fig. 5).
- H_0: Los residuos de la variable calificación proviene de una población normal.
- H_1: Los residuos de la variable calificación no proviene de una población normal.
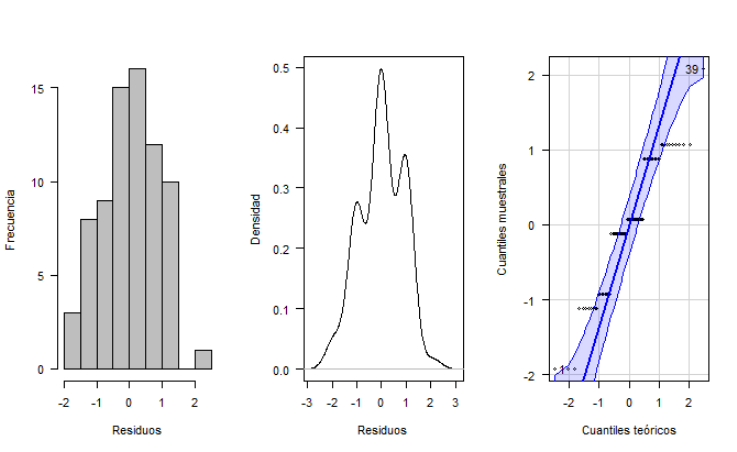
Fig. 5. Histograma, densidad y cuantiles teóricos vs cuantiles muestrales para los residuos.
Fuente: elaboración propia.
Para tener la certeza del cumplimiento de este supuesto se realizó la prueba de Shapiro-Wilk encontrándose un p-valor de 0.00032 y, por lo tanto, se rechaza la hipótesis nula, debido a que el p-valor es menor al valor del nivel de significancia (alfa=0,05), por lo que se concluye que los residuos de la variable de interés no están normalmente distribuidos con media cero y varianza constante. Por tanto, se asume con más confianza la respuesta por el test de Kruskal-Wallis cómo estadístico no paramétrico y por tanto se puede seguir asumiendo la diferencia significativa entre los grupos de prueba.
4.4. Independencia de los Residuos
Este supuesto requiere que la probabilidad de que el residuo de una observación cualquiera tenga un determinado valor, no debe depender de los valores de los otros residuos, en teoría esto se cumplió al realizar la aleatorización de los tratamientos, pero se realizó la prueba de Durbin-Watson (DW) para tener certeza del cumplimiento de este supuesto. Se debe tener en cuenta que, si el valor del estadístico DW está próximo a 2 entonces los residuos no están auto-correlacionados. Si su valor es 0 hay autocorrelación perfecta positiva. Si tiene un valor de 4 existe autocorrelación perfecta negativa. Al realizar la prueba de independencia de residuos de las calificaciones se determinó que los residuos no están correlacionados, debido a que el DW está próximo a 2 (2,1803) y el p-valor=0,4960 es superior al nivel de significancia alfa de 0,05 por lo que se concluye que existe independencia de los residuos.
5. CONCLUSIONES
El STI propuesto en este artículo, presenta una total funcionalidad integrando un modelo de personalización adaptativa de estrategias pedagógicas con la técnica de CBR en su módulo tutor, desde un ámbito específico de educación para la salud: Enseñanza de protocolos de atención de sífilis gestacional y congénita. Para esto se desarrolló una adaptación del algoritmo CBR de tal manera que aprovechara las potencialidades del metamodelo Metagogic. Los resultados de este estudio brindan un primer acercamiento de la personalización del aprendizaje en este tópico específico de educación para la salud. Estos resultados indican que el grupo que utilizó el STI obtuvo un mejor logro de aprendizaje frente al otro grupo que aprendió esta temática de manera tradicional. Esto podría sugerir que el uso de aplicaciones de este tipo, en educación para la salud, facilitaría la creación de nuevos escenarios de aprendizaje que posibiliten un aprendizaje significativo acorde a las características y necesidades de los estudiantes. El STI descrito en el presente artículo, provee a los profesionales de la salud una herramienta de aprendizaje personalizado al que pueden acceder en cualquier momento y lugar.
Teniendo en cuenta lo anterior, como trabajo futuro se propone la creación de un sistema computacional de personalización del aprendizaje que utilice técnicas de Machine Learning y que al ser implementado en este tipo de poblaciones puedan ser comparado con el sistema propuesto en este estudio y de esa manera verificar si la técnica empleada para la personalización del aprendizaje influye sobre el logro de aprendizaje de los estudiantes.
AGRADECIMIENTOS
Los autores agradecen a la Universidad de Córdoba - Colombia específicamente a su Vicerrectoría de Investigación y Extensión por el financiamiento otorgado al proyecto: Desarrollo de un Sistema Tutor Inteligente para el aprendizaje del protocolo de atención temprana de sífilis gestacional y congénita, código FCS-02-19, mediante convocatoria interna de proyectos de investigación de esta misma universidad. Al igual se extiende agradecimiento al Departamento de Enfermería de esta misma universidad por permitir desarrollar la investigación en sus instalaciones, y a los grupos de investigación Huellas y EDUTLAN por el recurso humano proporcionado para este estudio.
REFERENCIAS
[1] A. Klašnja-Milićević, B. Vesin, M. Ivanović, y Z. Budimac, «E-Learning personalization based on hybrid recommendation strategy and learning style identification», Comput. Educ., vol. 56, n.o 3, pp. 885-899, 2011, doi: https://doi.org/10.1016/j.compedu.2010.11.001.
[2] G. Bahg, «The Effects of Personalization on Category Learning», 2021, [En línea]. Disponible en: http://rave.ohiolink.edu/etdc/view?acc_num=osu1638475531086215
[3] M. Lefevre, S. Jean-Daubias, y N. Guin, «An approach for unified personalization of learning», jun. 2022, doi: https://doi.org/10.48550/arXiv.2309.02856 Focus to learn more.
[4] A. Gomez, M. Fernando, y C. Piñeres, «Meta-Modeling Process of Pedagogical Strategies in Intelligent Tutoring Systems Personalization of pedagogical strategies in Intelligent Tutoring Systems», 2018, doi: 10.1109/ICCI-CC.2018.8482046.
[5] M. Lefevre, «Processus unifié pour la personnalisation des activités pédagogiques: méta-modèle, modèles et outils», 2009.
[6] B. Clément, «Adaptive Personalization of Pedagogical Sequences using Machine Learning», l’Université de Bordeaux, 2019. [En línea]. Disponible en: https://hal.inria.fr/tel-01968241/file/CLEMENT_BENJAMIN_2018.pdf
[7] L. Marquez, H. Zapa, y A. Gomez, «Design of a Cognitive Control Mechanism for a Goal-based Executive Function of a Cognitive System», en Proceedings of the Ninth Goal Reasoning Workshop, Ohio, Estados Unidos, 2021, p. 8. [En línea]. Disponible en: https://sravya-kondrakunta.github.io/9thGoal-Reasoning-Workshop/papers/Paper_9.pdf
[8] Z. Li, L. Yee, y N. Sauerberg, «Getting too personal(ized): The importance of feature choice in online adaptive algorithms», p. 12, 2020.
[9] A. Klašnja-Milićević, B. Vesin, M. Ivanović, y Z. Budimac, «E-Learning personalization based on hybrid recommendation strategy and learning style identification», Comput. Educ., vol. 56, n.o 3, pp. 885-899, 2011, doi: https://doi.org/10.1016/j.compedu.2010.11.001.
[10] G. Bahg, «The Effects of Personalization on Category Learning», 2021, [En línea]. Disponible en: http://rave.ohiolink.edu/etdc/view?acc_num=osu1638475531086215
[11] M. Lefevre, S. Jean-Daubias, y N. Guin, «An approach for unified personalization of learning», jun. 2022, doi: https://doi.org/10.48550/arXiv.2309.02856 Focus to learn more.
[12] A. Gomez, M. Fernando, y C. Piñeres, «Meta-Modeling Process of Pedagogical Strategies in Intelligent Tutoring Systems Personalization of pedagogical strategies in Intelligent Tutoring Systems», 2018, doi: 10.1109/ICCI-CC.2018.8482046.
[13] M. Lefevre, «Processus unifié pour la personnalisation des activités pédagogiques: méta-modèle, modèles et outils», 2009.
[14] B. Clément, «Adaptive Personalization of Pedagogical Sequences using Machine Learning», l’Université de Bordeaux, 2019. [En línea]. Disponible en: https://hal.inria.fr/tel-01968241/file/CLEMENT_BENJAMIN_2018.pdf
[15] L. Marquez, H. Zapa, y A. Gomez, «Design of a Cognitive Control Mechanism for a Goal-based Executive Function of a Cognitive System», en Proceedings of the Ninth Goal Reasoning Workshop, Ohio, Estados Unidos, 2021, p. 8. [En línea]. Disponible en: https://sravya-kondrakunta.github.io/9thGoal-Reasoning-Workshop/papers/Paper_9.pdf
[16] Z. Li, L. Yee, y N. Sauerberg, «Getting too personal(ized): The importance of feature choice in online adaptive algorithms», p. 12, 2020.
[17] M. Zanker, L. Rook, y D. Jannach, «Measuring the impact of online personalisation: Past, present and future», Int. J. Hum.-Comput. Stud., vol. 131, pp. 160-168, nov. 2019, doi: 10.1016/j.ijhcs.2019.06.006.
[18] M. Kravcik et al., Requirements and Solutions for Personalized Adaptive Learning. 2005. [En línea]. Disponible en: https://hal.archives-ouvertes.fr/hal-00590961
[19] M. F. Caro, «Metamodel for personalized adaptation of pedagogical strategies using metacognition in Intelligent Tutoring Systems», Tesis Doctoral, Universidad Nacional de Colombia, Medellín, Colombia, 2015. Accedido: 29 de julio de 2021. [En línea]. Disponible en: https://repositorio.unal.edu.co/handle/unal/55505
[20] A. Gómez, L. Márquez, H. Zapa, y M. Florez, «GDA-Based Tutor Module of an Intelligent Tutoring System for the Personalization of Pedagogic Strategies», en Emerging Trends in Intelligent and Interactive Systems and Applications, M. Tavana, N. Nedjah, y R. Alhajj, Eds., en Advances in Intelligent Systems and Computing. Cham: Springer International Publishing, 2021, pp. 742-750. doi: 10.1007/978-3-030-63784-2_92.
[21] J. Joy y R. V. G. Pillai, «Review and classification of content recommenders in E-learning environment», J. King Saud Univ.-Comput. Inf. Sci., 2021, [En línea]. Disponible en: https://doi.org/10.1016/j.jksuci.2021.06.009
[22] S. Sarwar, Z. U. Qayyum, R. García-Castro, M. Safyan, y R. F. Munir, «Ontology based E-learning framework: A personalized, adaptive and context aware model», Multimed. Tools Appl., vol. 78, n.o 24, pp. 34745-34771, dic. 2019, doi: 10.1007/s11042-019-08125-8.
[23] E. Delozanne, C. Vincent, B. Grugeon, J.-M. Gélis, J. Rogalski, y L. Coulange, «From errors to stereotypes: Different levels of cognitive models in school algebra», presentado en E-Learn: World Conference on E-Learning in Corporate, Government, Healthcare, and Higher Education, Association for the Advancement of Computing in Education (AACE), 2005, pp. 262-269. [En línea]. Disponible en: https://www.learntechlib.org/p/21181/
[24] A. Mitrovic, «A knowledge-based teaching system for SQL», presentado en Proceedings of ED-MEDIA, Citeseer, 1998, pp. 1027-1032. [En línea]. Disponible en: https://www.csse.canterbury.ac.nz/tanja.mitrovic/702.pdf
[25] J. A. Jiménez Builes, «Un modelo de planificación instruccional usando razonamiento basado en casos en sistemas multi-agente para entornos integrados de sistemas tutoriales inteligentes y ambientes colaborativos de aprendizaje», Tesis Doctoral, Universidad Nacional de Colombia, Colombia, 2006. Disponible en: https://repositorio.unal.edu.co/handle/unal/11028
[26] E. G. Nihad, K. Mohamed, y E.-N. El Mokhtar, «Designing and modeling of a multi-agent adaptive learning system (MAALS) using incremental hybrid case-based reasoning (IHCBR).», Int. J. Electr. Comput. Eng. 2088-8708, vol. 10, n.o 2, 2020, doi: 10.11591/ijece.v10i2.pp1980-1992.
[27] «Review and classification of content recommenders in E-learning environment», J. King Saud Univ. - Comput. Inf. Sci., jul. 2021, doi: 10.1016/j.jksuci.2021.06.009.
[28] S. H. Almurshidi, S. S. A. Naser, y S. S. Abu, «Design and Development of Diabetes Intelligent Tutoring SystemDesign and Development of Diabetes Intelligent Tutoring System», Eur. Acad. Res., vol. 4, n.o 9, pp. 8117-8128, 2016.
[29] S. Matthews, «Integrating Technology Acceptance Model and Health Belief Model Factors to Better Estimate Intelligent Tutoring System Use for Surge Capacity Public Health Events and Training», Doctoral, University of Central Florida, Estados Unidos, 2020. [En línea]. Disponible en: https://stars.library.ucf.edu/etd2020/381
[30] K. M. Bauer, M. A. Corcorran, J. Z. Budak, C. Johnston, y D. H. Spach, «Leveraging E-Learning Infrastructure in Times of Rapid Change: Use of the National Sexually Transmitted Diseases Curriculum in the Era of COVID-19», Sex. Transm. Dis., vol. 48, n.o 8 Suppl, pp. S50-S53, ago. 2021, doi: 10.1097/OLQ.0000000000001462.
[31] L. H. A. Bos-Bonnie, J. E. A. M. van Bergen, E. te Pas, M. A. Kijser, y N. van Dijk, «Effectiveness of an individual, online e-learning program about sexually transmitted infections: a prospective cohort study», BMC Fam. Pract., vol. 18, n.o 1, p. 57, dic. 2017, doi: 10.1186/s12875-017-0625-1.
[32] S. M. C. de Almeida, L. M. Brasil, H. S. Carvalho, E. Ferneda, y R. P. Silva, «The Diagnosis Support System for Ischemic Cardiopathy: A Case Study in the Context of IACVIRTUAL Project», en World Congress on Medical Physics and Biomedical Engineering 2006, vol. 14, R. Magjarevic y J. H. Nagel, Eds., en IFMBE Proceedings, vol. 14. , Berlin, Heidelberg: Springer Berlin Heidelberg, 2007, pp. 3677-3680. doi: 10.1007/978-3-540-36841-0_931.
[33] M. C. Duffy y R. Azevedo, «Motivation matters: Interactions between achievement goals and agent scaffolding for self-regulated learning within an intelligent tutoring system», Comput. Hum. Behav., vol. 52, pp. 338-348, nov. 2015, doi: 10.1016/j.chb.2015.05.041.
[34] M. de S. Dutra Davilla et al., «Cervical cancer tracking virtual learning object», Acta Paul. Enferm., vol. 34, jul. 2021, doi: 10.37689/acta-ape/2021AO00063.
[35] C. Gonzalez et al., «ITS-TB: an intelligent tutoring system to provide e-learning in public health», en 16th EAEEIE conference, Lappeenranta, 2005. [En línea]. Disponible en: https://www.researchgate.net/publication/228623709
[36] C. S. Hunt, D. Panigrahi, y A. Momenipour, «Augmenting the information systems curriculum with a course in health informatics», vol. 2, n.o 1, p. 15, 2015.
[37] M. Royo-Leon et al., SEXWISE: An IBM Watson-Powered Mobile Application to Promote Sexual Education. 2016. [En línea].
[38] S. P. Somashekhar et al., «Watson for Oncology and breast cancer treatment recommendations: agreement with an expert multidisciplinary tumor board», Ann. Oncol., vol. 29, n.o 2, pp. 418-423, feb. 2018, doi: 10.1093/annonc/mdx781.
[39] G. E. Thibault, «The future of health professions education: Emerging trends in the United States», FASEB BioAdvances, vol. 2, n.o 12, pp. 685-694, 2020, doi: 10.1096/fba.2020-00061.
[40] B. Williamson, «Computing brains: learning algorithms and neurocomputation in the smart city», Inf. Commun. Soc., vol. 20, n.o 1, pp. 81-99, ene. 2017, doi: 10.1080/1369118X.2016.1181194.
[41] C. A. Ahumada, M. H. Lavalle, y M. V. Chamorro, «Sífilis gestacional: enfermedad de interés en salud pública, Córdoba-Colombia, 2015», Rev. Cuid., vol. 8, n.o 1, pp. 1449-1458, 2017, doi: https://doi.org/10.15649/cuidarte.v8i1.350.
[42] L. A. D. Cruz, «Sífilis gestacional: un problema de salud pública», Rev. Fac. Med., vol. 59, n.o 3, pp. 163-165, 2011.
[43] M. H. Owais, Development of Intelligent Systems to Optimize Training and Real-World Performance Amongst Health Care Professionals. The University of Toledo, 2019.
[44] K.-C. Pai, B.-C. Kuo, C.-H. Liao, y Y.-M. Liu, «An application of Chinese dialogue-based intelligent tutoring system in remedial instruction for mathematics learning», Educ. Psychol., vol. 41, pp. 1-16, feb. 2020, doi: 10.1080/01443410.2020.1731427.
[45] A. Gomez, «Design of a Self-Control Mechanism for an GDA-Based Tutor Module of an Intelligent Tutoring System», 2021, [En línea]. Disponible en: https://sravya-kondrakunta.github.io/9thGoal-Reasoning-Workshop/papers/Paper_8.pdf
[46] A. A. Gómez, E. P. Flórez, y L. A. Márquez, «Design of the tutor module for an intelligent tutoring system (ITS) based on science teachers’ pedagogical content knowledge (PCK)», presentado en International Congress on Education and Technology in Sciences, Springer, 2019, pp. 141-157. doi: https://doi.org/10.1007/978-3-030-45344-2_12.
[47] R. M. Felder y L. Silverman, «LEARNING AND TEACHING STYLES IN ENGINEERING EDUCATION», Eng. Educ., vol. 78, p. 10, 1988.
 1,
MSc. Adán Gómez Salgado
1,
MSc. Adán Gómez Salgado