Revista Colombiana de
Tecnologías de Avanzada
Tecnologías de Avanzada
Recibido: 15 de abril de 2023
Aceptado: 18 de julio de 2023
Aceptado: 18 de julio de 2023
SISTEMA DE IDENTIFICACIÓN DE ENFERMEDADES Y PLAGAS EN EL CULTIVO DE SANDÍA
DISEASES AND PESTS IDENTIFICATION SYSTEM IN WATERMELON CULTIVATION
 Raúl Cueto Morelo*, Juan Atencio Flórez*, Jorge Eliécer Gómez Gómez*
Raúl Cueto Morelo*, Juan Atencio Flórez*, Jorge Eliécer Gómez Gómez*
* Universidad de Córdoba, Facultad de ingeniería, Ingeniería de Sistemas y Telecomunicaciones, Semillero de Investigación Pervasive Computing.
Centro de desarrollo Lorica.
E-mail: {rcuetomorelo, atencioflorez61, jeliecergomez}@unicordoba.edu.co
DISEASES AND PESTS IDENTIFICATION SYSTEM IN WATERMELON CULTIVATION
Raúl Cueto Morelo*, Juan Atencio Flórez*, Jorge Eliécer Gómez Gómez*
* Universidad de Córdoba, Facultad de ingeniería, Ingeniería de Sistemas y Telecomunicaciones, Semillero de Investigación Pervasive Computing.
Centro de desarrollo Lorica.
E-mail: {rcuetomorelo, atencioflorez61, jeliecergomez}@unicordoba.edu.co
Cómo citar: Cueto Morelo, R., Atencio Flórez, J., & Gómez Gómez, J. E. (2023). SISTEMA DE IDENTIFICACIÓN DE ENFERMEDADES Y PLAGAS EN EL CULTIVO DE SANDÍA. REVISTA COLOMBIANA DE TECNOLOGIAS DE AVANZADA (RCTA), 2(42), 93–104. https://doi.org/10.24054/rcta.v2i42.2674
Derechos de autor 2023 Revista Colombiana de Tecnologías de Avanzada (RCTA).
Esta obra está bajo una licencia internacional Creative Commons Atribución-NoComercial 4.0.

Esta obra está bajo una licencia internacional Creative Commons Atribución-NoComercial 4.0.
Resumen: En este estudio se desarrolló una aplicación móvil bajo el nombre “Sandiapp”, con el objetivo de identificar las diferentes plagas y enfermedades que afectan el cultivo de sandía en el municipio de San Bernardo del Viento - Córdoba. Para cumplir con este objetivo, se realizó un levantamiento de campo utilizando el método cuantitativo, como estudio sistemático de los hechos dentro de los cuales se presentó el caso, para obtener información útil para formular la propuesta y sustentar la propuesta a través de un sistema que a través del aprendizaje automático identifica los tipos de plagas y enfermedades que afectan los cultivos de sandía. Para el desarrollo de este proyecto se utilizaron ciertos algoritmos de visión artificial, el cual consiste en reconocer formas, distancias, ángulos, colores y determinar las dimensiones de la planta de sandía. Para realizar este procedimiento se ha considerado la forma y tamaño de la lámina. A través de las pruebas realizadas durante el desarrollo de este trabajo se concluye que: Mediante la implementación del sistema de visión artificial se demostró el incremento en el porcentaje de agricultores, los cuales ahora cuentan con un mayor nivel de información sobre plagas y enfermedades del cultivo de sandía.
Palabras clave: Procesamiento de imágenes, aprendizaje informático o automatizado, aprendizaje supervisado, aprendizaje no supervisado, sandía, inteligencia artificial, visión artificial.
Abstract: In this study, a mobile application was developed under the name “Sandiapp”, with the aim of identifying the different pests and diseases that affect the cultivation of watermelon in the municipality of San Bernardo del Viento - Córdoba. To meet this objective, a field survey was carried out using the quantitative method, as a systematic study of the facts within which the case was presented, to obtain useful information to formulate the proposal and support the proposal through a system that through machine learning identifies the types of pests and Diseases that affect watermelon crops. For the development of this project, certain artificial vision algorithms were used, which consists of recognizing shapes, distances, angles, colors and determining the dimensions of the watermelon plant. To carry out this procedure, the shape and size of the sheet has been considered. Through the tests carried out during the development of this work, it is concluded that: Through the implementation of the artificial vision system, the increase in the percentage of farmers was demonstrated, which now has a higher level of information on pests and diseases of the watermelon crop.
Keywords: Image processing, computer or automated learning, supervised learning, unsupervised learning, watermelon, artificial intelligence, artificial vision.
It is of utmost importance to achieve a precise distinction between pests and diseases in watermelon production, since this is essential to sustainably increase yields in agriculture. For this reason, the concept of Agriculture 4.0 has been adopted, which encompasses a variety of technologies, devices, protocols and computing approaches designed to improve agricultural processes (Gómez-Camperos, J.A., Jaramillo, H.Y., & Guerrero-Gómez, G. 2021). The system to identify and classify diseases in watermelon crops makes use of advanced techniques and technology, especially image processing, with the purpose of determining the moment in which the initial phase of Alternaria emerges, a disease that is common in crops. of watermelon and which is related to different types of affected leaves in watermelon. In addition, this technology has also been used to detect the three most common pests in crops: Alternaria, late blight and viral diseases (Martínez-Corral, L., Martínez-Rubín, E., Flores-García, F., Castellanos, G.C., Juarez, A.L., & López, M. 2009).
In this context, this study contributes to the advancement of a system based on machine learning that can perform diagnoses in the field by personnel without specific training, but taking advantage of the knowledge of expert coffee growers (Santa María Pinedo, J.C., Ríos López, C.A., Rodríguez Grández, C., & García Estrella, C.W. 2021). This system is designed to identify visual signs of the most common plant diseases, using affordable, powerful and highly reliable hardware. After selecting a deep network architecture with outstanding performance in disease classification, we fine-tuned the model parameters to optimize its reproducibility without facing overfitting issues.
Digital image analysis methods for identification of diseases and pests in crops: an exhaustive review (Gómez-Camperos, J.A., Jaramillo, H.Y., & Guerrero-Gómez, G. 2021): Pest detection relies heavily on manual observation, which can lead to mistakes due to individual interpretation. The purpose of this literature review is to examine the different image processing strategies used in disease and pest control in various agricultural contexts.
Identification of pathologies in potato crops through image processing (Martínez-Corral, L., Martínez-Rubín, E., Flores-García, F., Castellanos, G.C., Juarez, A.L., & López, M. 2009): This analysis describes the tactics and techniques implemented in a system for detecting and classifying diseases in potato crops, taking advantage of image processing to identify the initial phase of development of Alternaria spp. Although this disease is common in potato crops, it has its origin in various conditions.
A Machine Learning Model for the Diagnosis of Diseases in Coffee Plants (Santa María Pinedo, J.C., Ríos López, C.A., Rodríguez Grández, C., & García Estrella, C.W. 2021): This system is designed to analyze visual characteristics of the most common diseases in coffee plants, using low-cost, resistant and reliable devices. A deep network structure with high classification performance is implemented, and the model parameters are adapted to optimize its reproduction without inducing overfitting.
Creation of a database for the characterization of the alfalfa plant, using a computer vision approach (Malpartida, S., & Ángel, E.T. 2011): The central purpose of this project was to develop a visual tool that facilitates the evaluation of nutritional insufficiencies (N, P and K) and water stress conditions in alfalfa plants. This reporting system fuses all of the above elements to provide an accurate representation of the condition of alfalfa plants. Analysis of visual patterns through a computer vision platform in MATLAB (Vargas, O.L., & Perrez, Á.A. 2019): The objectives focus on the improvement of pattern recognition using computer vision systems, the evaluation of the pattern identification process, the implementation of vision platforms computer vision and exploring the interaction between pattern recognition and computer vision systems.
Artificial vision system for the recognition and manipulation of objects using a robot arm (León León, R.A., Jara, B.J., Cruz Saavedra, R., Terrones Julcamoro, K., Torres Verastegui, A., & Aponte de la Cruz, M.A. 2020).
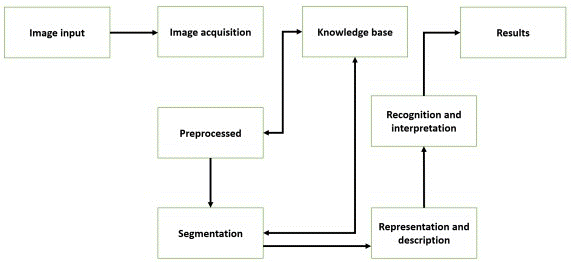
Image manipulation refers to the capture and alteration of images or video sequences for the purpose of extracting specific attributes or parameters, or to generate a new processed image as a result. It is crucial to note that the evolution of digital image processing methods derives from two fundamental fields of application: the improvement of visual information to simplify human interpretation and the automated processing of visual data for use in devices, which encompasses the transmission and/or conservation of this data (Ramírez Escalante, Boris. Procesamiento Digital de Imágenes). The effectiveness of an imaging system is closely connected to its components, of which six key aspects can be identified that are observable and differentiable (see figure 1): Capture: In this stage the acquisition of a visual image is carried out. Pretreatment: It encompasses techniques such as noise reduction and improvement of image details. Segmentation: It consists of the action of dividing an image into objects of interest. Description: Corresponds to the stage in which appropriate attributes are obtained to distinguish between different types of objects. Recognition: Refers to the process of assigning meaning to a set of identified objects.
Data acquisition: It is required to obtain images of watermelon plants in both healthy states and those affected by different pests and diseases. These images will constitute the training data set for the computer vision system.
Image conditioning: Before introducing images to the model, it is essential to apply a conditioning process to improve their quality and reduce noise. This could include actions such as correcting color balance, adjusting contrast, and removing unwanted backgrounds.
Feature Extraction: In order to facilitate the identification and categorization of pests and diseases, it is essential to obtain distinctive features from the images. This process may involve the application of computer vision algorithms, such as the Local Pattern Transform (LBP) or the Wavelet Transform, in order to capture salient patterns present in the images. These approaches allow us to recognize particular attributes that are specific to certain pests and diseases.
Contextual Modeling: The machine vision system must consider the context of the watermelon growing environment when carrying out identification and classification. This involves taking into account elements such as the shape of the leaves, the tone of the fruits, the detection of spots or damage, and any other relevant indicator to discern specific pests or diseases.
Model Training: It is essential to train a machine learning model and an advanced strategy to face this challenge involves the use of a Convolutional Neural Network (CNN), using the set of labeled images. The model must acquire the ability to identify distinctive patterns and traits related to various pests and diseases.
Verification and Tuning: Once trainings is completed, the model must undergo verification using a separate data set. It may be necessary to make adjustments to hyper parameters or modifications to the model to improve its efficiency and accuracy.
Commissioning and Implementation: Once the model has been verified and fine-tuned, it is possible to put it into operation in a computer vision system capable of processing images simultaneously. This could involve using cameras or sensors to capture images of watermelon plants in the field and transmit them to the processing system. See figure 3.
Since this project is a mobile application, its operation has been designed to run on the Android platform (version 4.4), which demonstrates greater compatibility with a wide range of mobile devices (smartphones) available on the market.
The system structure adopts a client-server approach, where clients interact with the interface, perform actions, update views, and load data. The architecture maintains the state of the application, manages requests to and from the server, and controls the presentation of information.
When an operation is performed on the application, such as verifying a user's access, the app sends an HTTP request (based on the DART® API) to a web server. This server contains data stored in a database, which is hosted on a web service for the purpose of offering online advice.
The web server is responsible for recording or updating information, responding to requests from client applications, assigning tasks to web services, managing data storage or extraction operations from the database, updating system tables, loading data into a server or run specific queries. Back to the mobile application, it processes and presents the information in JSON© format. The structure of our system is visualized in the Graphical Abstract that has been prepared.


One of the main challenges facing agriculture today is the need to achieve high yields without depleting natural resources. To ensure sustainability in agriculture, it must be productive from an economic point of view, but must also consider the preservation of natural resources and environmental integrity at local, regional and global levels. Furthermore, it is crucial to take social and cultural diversity into account when exploring effective alternatives, as suggests. Watermelon, being a highly delicate fruit, is susceptible to pests and diseases that affect specific parts of the plant, particularly the leaves. In this context, relevant information about the pest detection process is provided. According to (Ramírez Escalante, Boris. Procesamiento Digital de Imágenes, 2006), in an-interview, farmers often identify pests intuitively by going to the field and carefully observing the crops. Although experience may guide your observations, it is common for the effects of pests or diseases to be consistent, such as the yellowing of leaves that is often associated with pests such as aphid and diseases such as fusarium. However, less experienced farmers could make mistakes and resort to incorrect use of agrochemicals.
Additionally, according to (J. M. G. Recinos, Rendimiento de híbridos de sandía tipo personal; valle del Motagua, Zacapa., Zacapa, 2015), artificial intelligence refers to the creation of elements that exhibit intelligent behaviors, which include the ability to learn, adapt to changing contexts, manifest creativity and other abilities, and all this in combination with ability to perform such functions. This field is exceptionally diverse, spanning areas as broad as neuroscience, psychology, information technology, cognitive science, physics, mathematics, and much more. Furthermore, a variety of perceptions and actions can be obtained and generated through physical and mechanical sensors in devices, as well as through electrical or light signals in computer systems. These processes are performed through input and output modules in programs and their software environment. Examples of these procedures range from monitoring systems and scheduling automation to response diagnostics, customer interaction, handwriting recognition, voice identification, and pattern detection. See figure 6. Artificial intelligence is already widely implemented in various sectors, such as economics, medicine, engineering and the armed forces.
Likewise, it is applied in numerous software applications, video games and strategies, such as computerized chess and other electronic devices. By exhaustive examination of the literature.
y = np.array(etiquetas)
Here, the lists images and labels are converted into NumPy arrays X and y, respectively. This is required to work with the functions and methods provided by the NumPy library and SciKit-Learn.
This line prints the original dimensions of the images. X.shape returns a tuple containing the dimensions of the array.
Here, images are "flattened" using reshape. This means that they transform from two-dimensional arrays to one-dimensional arrays. This is common in image processing so that each image is converted into a one-dimensional vector of pixels.
Split the training and testing data set: X_entrenamiento, X_prueba, y_entrenamiento, y_prueba = train_test_split(X, y, test_size=0.3, random_state=1)
The data set is split into training (X_training, y_training) and test sets (X_testing, y_testing) using the train_test_split function of SciKit-Learn.
30% of the data set is used as a test set (test_size=0.3) and a random seed (random_state=1) is set to ensure reproducibility.
A decision tree classifier object is created using SciKit-Learn's DecisionTreeClassifier class.
The decision tree is trained on the training set (X_training, y_training) using the fit method. This means that the model will learn to make decisions based on the features of the images to predict the labels.
The decision tree is used to make predictions on the test set (X_test) using the predict method.
print("Precisión: ", precision)
Finally, the accuracy of the model is calculated by comparing the predicted labels (y_prediction) with the actual labels of the test set (y_test) using the accuracy_score function of SciKit-Learn. The accuracy is printed on the screen.
In summary, this code performs a complete process of training and evaluating a decision tree-based classification model using image and label datasets. The accuracy of the model is calculated and displayed as a result.
We observe the results of the decision tree algorithm.
Result: decision tree 19002<=0.45
So, in summary, what this code does is take the trained decision tree (tree), generate a text representation of that tree, and then print it to the console. This text representation provides information about how the tree is split at each node, what features are used at each split, and what the decision criteria are at each node. This is useful for understanding the internal logic of the decision tree and how it makes decisions based on input features. Feature names are also included for better understanding (Gómez et al., 2023; Oviedo et al.,2019).
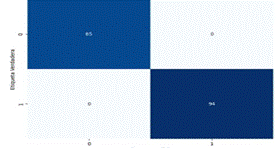
sns.heatmap from the Seaborn library is used to plot the confusion matrix as a heat map. confusion_matrix is the confusion matrix calculated in the previous step, and annot=True indicates that the values within the heatmap cells should be displayed.
fmt="d" specifies the format of values inside cells (integers).cmap="Blues" establece el esquema de colores a utilizar en el mapa de calor. En este caso, se usa el esquema de colores "Blues" que va desde tonos más claros a más oscuros para representar los valores. cbar=False prevents a color bar from being displayed on the side of the heat map.
Labels are then added to the x and y axes to indicate the true and predicted labels, and a title is added to the figure.
Finally, the visualization is shown with plt.show(). In summary, this code calculates the confusion matrix to evaluate the performance of the classification model and creates a visualization of the confusion matrix in the form of a heat map for easy interpretation of how the model is right or wrong in its predictions.
A Sequential Neural Network model is created which is a linear stack of layers.
The first layer is a Dense layer with 64 units and ReLU activation ('relu'). This layer has an input with the same shape as the input characteristics of the data (input_shape=(X_training.shape[1],)).
The second layer is another dense layer with a single unit and sigmoid activation ('sigmoid'). This layer is commonly used in binary classification problems to obtain a probability between 0 and 1 as output.
The model is compiled using the 'adam' optimizer, which is a widely used optimizer in training neural networks.
The loss function is specified as 'binary_crossentropy', which suggests that the problem is binary classification. This loss function measures how well the model fits the true labels.
It is also specified that we want to track the accuracy metric during training.
The model is trained using the training set (X_training and y_training) for a specific number of epochs (10 in this case) using the fit method.
The parameter batch_size=32 indicates that a batch size of 32 samples will be used at a time during training. This helps speed up the training process and can improve training stability.
Se evalúa el modelo utilizando el conjunto de prueba (X_prueba e y_prueba) utilizando el método evaluate.
El resultado de la evaluación se almacena en la variable evaluacion, que contiene la pérdida y la precisión (accuracy) del modelo.
Finalmente, se imprime la precisión del modelo en el conjunto de prueba.
The importance of this code is that it shows how to build, train and evaluate a neural network model to solve a binary classification problem. Neural networks are a powerful deep learning technique and are used in a variety of applications, from image processing to natural language processing
and more. Understanding how to design and train neural network models is critical for advanced data science and machine learning applications. The accuracy of the model on the test set provides information about its performance on unseen data and can guide decisions about its usefulness in real applications.
Performance on tabular data and simple features: Decision trees perform well on tabular data with simple features. They are good for problems where the relationships between features and labels are clear and non-linear.
Sensitivity to noisy data: Decision trees can be sensitive to noisy data or outliers. They can be overfitted if not properly controlled.
Ease of training and prediction: Decision trees are relatively fast to train and predict compared to more complex models such as neural networks.
Requires more data and resources: Neural networks typically require larger data sets and more computational resources to train properly. They may also require more hyper parameter adjustments.
Less interpretability: Neural networks tend to be less interpretable than decision trees. The internal structure of a neural network can be complex and difficult to understand.
If the problem is more complex and requires capturing non-linear relationships or sophisticated patterns in the data, a neural network might be more appropriate. However, this could require more data and computational resources.
In general, it is good practice to test various types of models, including decision trees and neural networks, and compare their results using evaluation metrics such as precision, recall, and F1-score on an independent test set. This will help you determine which model best suits your specific problem. You can also consider interpretability and available resources when making your decision.
Through the implementation of the computer vision system, farmers have experienced an increase in their understanding of pests and diseases that affect watermelon crops. According to the results of the survey, it can be deduced that 81.2% of respondents have stated that the information provided has enriched their level of knowledge, meeting their expectations by providing concise and complete details. On the other hand, before the introduction of the software, only 26.5% of farmers had mentioned having basic and secondary levels of information. Evidently, the level of digitalization has seen considerable improvement.
Additionally, the inclusion of machine vision systems has significantly increased the proportion of farmers who now have a better understanding of recommended agricultural chemicals. According to the survey, 82.6% of the population currently claims that the information provided has contributed to raising their level of awareness. In contrast, before the implementation of the software, only 5.8% of farmers had expressed having a moderate level of information. Again, it can be inferred that the system has managed to meet its stated objectives.
In summary, the development of an artificial vision system with the purpose of identifying pests and diseases in watermelon cultivation constitutes an innovative and effective solution to the challenges faced by agriculture. This solution combines advanced technologies such as image processing and machine learning to offer accurate and reliable tools that support farmers in the timely detection and management of pests and diseases that harm watermelon crops. Through advanced cameras and algorithms, machine vision technology has the ability to analyze images of watermelon plants for signs and symptoms of pests and diseases. This allows for rapid and accurate identification, facilitating informed decision-making and the implementation of targeted control measures. Additionally, the system offers various advantages for farmers. Perform thorough and agile inspections over large crop areas, reducing the need for manual inspections and saving time and resources. It also provides objective evaluations and uniforms, reduces human errors and allows the adoption of early preventive measures.
The introduction of an artificial vision system designed to recognize pests and diseases in watermelon cultivation presents great potential to increase the productivity and profitability of farmers, while minimizing the environmental impact by reducing the use of pesticides and other chemicals. This approach is emerging as a highly promising tool in the field of precision agriculture, paving the way for future advances in crop control and management.
In summary, the integration of the artificial vision system in watermelon production offers an extremely effective and efficient solution for the early detection and control of pests and diseases. Its ability to improve production efficiency, reduce costs and mitigate environmental impact makes it an invaluable resource for farmers facing crop health challenges. Below are some recommendations to further strengthen the development of artificial vision systems with regard to the identification of pests and diseases in watermelon cultivation:
Increase accuracy: Continuing to improve algorithms aimed at detecting and recognizing pests is crucial. This involves collecting a variety of high-resolution images to train the machine learning models, as well as conducting constant testing and validation to raise the accuracy and reliability of the system.
Expand the database: In order to optimize the effectiveness of the system, it is essential to establish and maintain an updated and extensive database that covers images of various pests, diseases and situations that affect watermelon cultivation. As this database grows in size and diversity, the system's ability to recognize and categorize a variety of challenges that may arise in crops will be greatly improved.
Integrate multiple technologies: Machine vision can be enriched with other technologies, such as temperature, humidity or soil quality sensors, to obtain a complete understanding of the status of watermelon crops. The combination of these technologies can provide a comprehensive assessment of plant health and enable more accurate and timely decisions in crop management. Develop an intuitive user interface: For farmers to get the most out of the machine vision system, it is essential to design a user interface that is easy to understand and use. This interface allows them to seamlessly interact with the system, access reports and results, and understand the recommendations and suggested actions.
Adaptability to different environments and conditions: Since watermelon crops can grow in various contexts and conditions.
As we consider geographic and environmental factors, it is important that machine vision systems are adaptable to a wide range of climates, watermelon types, and growing methods. This involves addressing differences in pest and disease incidence depending on specific conditions, ensuring the system is resilient and accurate in various scenarios. It is also crucial to encourage constant collaboration and receive continuous feedback.
Collaboration between researchers, farmers and agricultural technology experts becomes an essential component to ensure the constant evolution of this system. The contributions of end users are invaluable to identify areas of improvement and address the individual needs of producers regarding the detection and control of pests and diseases in watermelon crops.
The implementation of these recommendations can result in increasingly efficient and valuable artificial vision systems for the identification and management of pests and diseases in watermelon crops. This, in turn, will contribute to more productive, sustainable and profitable agriculture.
Ogata, K. (2004). Ingeniería de Control Moderna, Prentice Hall, Cuarta edición, Madrid.
Clymer, J. R. (1992). “Discrete Event Fuzzy Airport Control”. IEEE Trans. On Systems, Man, and Cybernetics, Vol. 22, No. 2.
Gómez-Camperos, J.A., Jaramillo, H.Y., & Guerrero-Gómez, G. (2021). Técnicas de procesamiento digital de imágenes para detección de plagas y enfermedades en cultivos: una revisión. INGENIERÍA Y COMPETITIVIDAD.
Martínez-Corral, L., Martínez-Rubín, E., Flores- García, F., Castellanos, G.C., Juarez, A.L., & López, M. (2009). Desarrollo de una base de datos para caracterización de alfalfa (Medicago sativa L.) en un sistema de visión artificial.
Santa María Pinedo, J.C., Ríos López, C.A., Rodríguez Grández, C., & García Estrella, C.W. (2021). Reconocimiento de patrones de imágenes a través de un sistema de visión artificial en MATLAB. Revista Científica de Sistemas e Informática.
Malpartida, S., & Ángel, E.T. (2011). Sistema de visión artificial para el reconocimiento y manipulación de objetos utilizando un brazo robot.
Vargas, O.L., & Perrez, Á.A. (2019). Implementación de un Sistema de Visión Artificial para la clasificación de naranja producida en el departamento del Quindío.
León León, R.A., Jara, B.J., Cruz Saavedra, R., Terrones Julcamoro, K., Torres Verastegui, A., & Aponte de la Cruz, M.A. (2020). DESARROLLO DE SISTEMA DE VISIÓN ARTIFICIAL PARA CONTROL DE CALIDAD DE BOTELLAS EN LA EMPRESA CARTAVIO RUM COMPANY. Ingeniería Investigación y Desarrollo.
Ramírez Escalante, Boris. Procesamiento Digital de Imágenes [en línea], Verona, [citado agosto, 2006].
J. M. G. Recinos, Rendimiento de híbridos de sandía tipo personal; valle del Motagua, Zacapa., Zacapa, 2015.
Bautista, R.A., Constante, P., Gordon, A., & Mendoza, D. (2019). Diseño e implementación de un sistema de visión artificial para análisis de datos NDVI en imágenes espectrales de cultivos de brócoli obtenidos mediante una aeronave pilotada remotamente.
Prócel, P.N., & Garcés, A.M. (2015). Diseño e implementación de un sistema de visión artificial para clasificación de al menos tres tipos de frutas.
Yandún Velasteguí, M.A. (2020). Detección de enfermedades en cultivos de Papa usando procesamiento de imágenes.
Martínez, F.H., Montiel, H., & Martínez, F. (2022). A Machine Learning Model for the Diagnosis of Coffee Diseases. International Journal of Advanced Computer Science and Applications.
Ortega, B.R., Biswal, R.R., & Sánchez-Delacruz, E. (2019). Detección de enfermedades en el sector agrícola utilizando Inteligencia Artificial. Res. Comput. Sci., 148, 419-427.
Zapata, V., & Alejandro, J.R. (2019). Diseño y desarrollo de un sistema prototipo de diagnóstico de afecciones en plantas de cítricos utilizando procesamiento de imágenes y aprendizaje profundo.
Pillajo, M.A., Pillajo, M.A., & Cabascango, A.S. (2019). Diagnóstico inteligente de enfermedades y plagas en plantas ornamentales.
Narciso Horna, W.A., & Manzano Ramos, E.A. (2021). Sistema de visión artificial basado en redes neuronales convolucionales para la selección de arándanos según estándares de exportación. Campus.
Huaccha, E.D. (2018). Desarrollo de un sistema de visión artificial para realizar una clasificación uniforme de limones.
Bautista, R.A., Constante, P., Gordon, A., & Mendoza, D. (2019). Diseño e implementación de un sistema de visión artificial para análisis de datos NDVI en imágenes espectrales de cultivos de brócoli obtenidos mediante una aeronave pilotada remotamente. Infociencia.
Tinajero, J., Acosta, L.A., Chango, E.F., & Moyon, J.F. (2020). Sistema de visión artificial para clasificación de latas de pintura por color considerando el espacio de color RGB.
Salazar, P., Ortiz, S., Hernandez, T.H., & Bermeo, N.V. (2016). Artificial Vision System Using Mobile Devices for Detection of Fusarium Fungus in Corn. Res. Comput. Sci., 121, 95-104.
hyar, B.S., & Birajdar, G.K. (2017). Computer vision based approach to detect rice leaf diseases using texture and color descriptors. 2017 International Conference on Inventive Computing and Informatics (ICICI), 1074-1078.
Yasir, R., Rahman, M.A., & Ahmed, N. (2014). Dermatological disease detection using image processing and artificial neural network. 8th International Conference on Electrical and Computer Engineering, 687-690.
P. P. Garcia Garcia, Reconocimiento de imagenes utilizando redes neuronales artificiales, Madrid, España, 2013.
Orduz, J. O., León, G. A., Chacón Díaz, A., Linares, V. M., & Rey, C. A. (2000). El cultivo de la sandía o patilla (Citrullus lanatus) en el departamento del Meta (No. Doc. 21998) CO- BAC, Bogotá.
González Sánchez, H. A. (1999). Impacto ambiental de la labranza mecánica convencional. Departamento de Ciencias Agropecuarias.
R. Jorge, Introducción a los sistemas de visión artificial, Madrid, España, 2011.
CHAVEZ, Procesamiento de imágenes [en linea], Puebla, Universidad de las Américas puebla [citado en 6 de Julio de 2015].
MATWORKS, Detección de bordes [en línea], [citado en 6 de octubre de 2015].
A. Marin Poatoni, Desarrollo de prototipo de aplicacion (APP), para dispositivos móviles basados en el sistema IOS, para el reconocimiento de objetos"Hojas" en imagenes, Motecillo, Mexico, 2014.
H. T. T., L. V. G. Bay, «Speeded-Up Robust,» EE. UU, 2006.
Gomez, J. G., Hernandez, V., & Ramirez- Gonzalez, G. (2023). Traffic classification in IP networks through Machine Learning techniques in final systems. IEEE Access.
Oviedo, B., Zambrano-Vega, C., & Gómez, J. (2019). Clasificador Bayesiano Simple aplicado al aprendizaje. Revista Ibérica de Sistemas e Tecnologias de Informação, 18, 74-85.
Palabras clave: Procesamiento de imágenes, aprendizaje informático o automatizado, aprendizaje supervisado, aprendizaje no supervisado, sandía, inteligencia artificial, visión artificial.
Abstract: In this study, a mobile application was developed under the name “Sandiapp”, with the aim of identifying the different pests and diseases that affect the cultivation of watermelon in the municipality of San Bernardo del Viento - Córdoba. To meet this objective, a field survey was carried out using the quantitative method, as a systematic study of the facts within which the case was presented, to obtain useful information to formulate the proposal and support the proposal through a system that through machine learning identifies the types of pests and Diseases that affect watermelon crops. For the development of this project, certain artificial vision algorithms were used, which consists of recognizing shapes, distances, angles, colors and determining the dimensions of the watermelon plant. To carry out this procedure, the shape and size of the sheet has been considered. Through the tests carried out during the development of this work, it is concluded that: Through the implementation of the artificial vision system, the increase in the percentage of farmers was demonstrated, which now has a higher level of information on pests and diseases of the watermelon crop.
Keywords: Image processing, computer or automated learning, supervised learning, unsupervised learning, watermelon, artificial intelligence, artificial vision.
1. INTRODUCTION
Challenges in plant health include difficulties caused by pests and diseases, which can lead to a decline of up to 30% in global production. Given that cultivated plants play a crucial role in human nutrition and have a significant impact on the economies of producing countries, it is clear that the damages derived from pests have both social and economic implications. These problems are the result of the interaction between aggressive pathogens, host organisms and favorable climatic conditions, creating what is known as the "Crop Disease Triangle." The environment encompasses the climatic conditions that generally promote the spread of pests. Some of the factors that favor their proliferation are rain, dew, air humidity and temperature, all of which affect the appearance, evolution and speed of pests. The correct identification of these problems has emerged as a constant challenge for farmers, who face new obstacles daily to safeguard their crops. Currently, the detection of diseases and pests in plants falls mainly on visual observation by farmers.It is of utmost importance to achieve a precise distinction between pests and diseases in watermelon production, since this is essential to sustainably increase yields in agriculture. For this reason, the concept of Agriculture 4.0 has been adopted, which encompasses a variety of technologies, devices, protocols and computing approaches designed to improve agricultural processes (Gómez-Camperos, J.A., Jaramillo, H.Y., & Guerrero-Gómez, G. 2021). The system to identify and classify diseases in watermelon crops makes use of advanced techniques and technology, especially image processing, with the purpose of determining the moment in which the initial phase of Alternaria emerges, a disease that is common in crops. of watermelon and which is related to different types of affected leaves in watermelon. In addition, this technology has also been used to detect the three most common pests in crops: Alternaria, late blight and viral diseases (Martínez-Corral, L., Martínez-Rubín, E., Flores-García, F., Castellanos, G.C., Juarez, A.L., & López, M. 2009).
In this context, this study contributes to the advancement of a system based on machine learning that can perform diagnoses in the field by personnel without specific training, but taking advantage of the knowledge of expert coffee growers (Santa María Pinedo, J.C., Ríos López, C.A., Rodríguez Grández, C., & García Estrella, C.W. 2021). This system is designed to identify visual signs of the most common plant diseases, using affordable, powerful and highly reliable hardware. After selecting a deep network architecture with outstanding performance in disease classification, we fine-tuned the model parameters to optimize its reproducibility without facing overfitting issues.
2. METHODOLOGY
2.1 Survey type
A field survey was carried out using the quantitative method, as a systematic study of the facts within which the case was presented, to obtain useful information to formulate the proposal and support the proposal through a system that, through machine learning, identifies the types of pests and diseases that affect watermelon cultivation. The basis of the established objectives. Likewise, a bibliographic study is carried out through books, scientific journals and electronic publications to delve into the different approaches to the research topic, and in this way valuable information is collected as scientific support for the project, expanding various theories, concepts and criteria.2.2 Population and Sample
2.2.1 Population
The aim is to create a system that, through machine learning, identifies the types of pests and diseases that affect watermelon cultivation in the municipality of San Bernardo. of the wind.2.2.2 Sample
A specific sample of the population will be taken, they are all watermelon planting farmers, making a total of 4 groups of 25 farmers.3. RELATED WORKS
Research useful for the progress of current activity is presented. Research has been discovered related to the development of this proposal for an application that, through the use of machine learning, can recognize the varieties of pests and diseases that impact watermelon cultivation.Digital image analysis methods for identification of diseases and pests in crops: an exhaustive review (Gómez-Camperos, J.A., Jaramillo, H.Y., & Guerrero-Gómez, G. 2021): Pest detection relies heavily on manual observation, which can lead to mistakes due to individual interpretation. The purpose of this literature review is to examine the different image processing strategies used in disease and pest control in various agricultural contexts.
Identification of pathologies in potato crops through image processing (Martínez-Corral, L., Martínez-Rubín, E., Flores-García, F., Castellanos, G.C., Juarez, A.L., & López, M. 2009): This analysis describes the tactics and techniques implemented in a system for detecting and classifying diseases in potato crops, taking advantage of image processing to identify the initial phase of development of Alternaria spp. Although this disease is common in potato crops, it has its origin in various conditions.
A Machine Learning Model for the Diagnosis of Diseases in Coffee Plants (Santa María Pinedo, J.C., Ríos López, C.A., Rodríguez Grández, C., & García Estrella, C.W. 2021): This system is designed to analyze visual characteristics of the most common diseases in coffee plants, using low-cost, resistant and reliable devices. A deep network structure with high classification performance is implemented, and the model parameters are adapted to optimize its reproduction without inducing overfitting.
Creation of a database for the characterization of the alfalfa plant, using a computer vision approach (Malpartida, S., & Ángel, E.T. 2011): The central purpose of this project was to develop a visual tool that facilitates the evaluation of nutritional insufficiencies (N, P and K) and water stress conditions in alfalfa plants. This reporting system fuses all of the above elements to provide an accurate representation of the condition of alfalfa plants. Analysis of visual patterns through a computer vision platform in MATLAB (Vargas, O.L., & Perrez, Á.A. 2019): The objectives focus on the improvement of pattern recognition using computer vision systems, the evaluation of the pattern identification process, the implementation of vision platforms computer vision and exploring the interaction between pattern recognition and computer vision systems.
Artificial vision system for the recognition and manipulation of objects using a robot arm (León León, R.A., Jara, B.J., Cruz Saavedra, R., Terrones Julcamoro, K., Torres Verastegui, A., & Aponte de la Cruz, M.A. 2020).
Table I. Comparative table with respect to related Works
| Article name | Prosecution of pictures | Neural networks | Artificial vision |
|---|---|---|---|
| Gómez-Camperos 2021 | + | - | - |
| Martínez-Corral 2009 | - | + | + |
| Santa María 2021 | + | - | + |
| Malpartida 2011 | + | - | - |
| Vargas 2019 | + | - | + |
| León León 2020 | - | + | - |
Image manipulation refers to the capture and alteration of images or video sequences for the purpose of extracting specific attributes or parameters, or to generate a new processed image as a result. It is crucial to note that the evolution of digital image processing methods derives from two fundamental fields of application: the improvement of visual information to simplify human interpretation and the automated processing of visual data for use in devices, which encompasses the transmission and/or conservation of this data (Ramírez Escalante, Boris. Procesamiento Digital de Imágenes). The effectiveness of an imaging system is closely connected to its components, of which six key aspects can be identified that are observable and differentiable (see figure 1): Capture: In this stage the acquisition of a visual image is carried out. Pretreatment: It encompasses techniques such as noise reduction and improvement of image details. Segmentation: It consists of the action of dividing an image into objects of interest. Description: Corresponds to the stage in which appropriate attributes are obtained to distinguish between different types of objects. Recognition: Refers to the process of assigning meaning to a set of identified objects.
Fig. 1. Stages of an artificial vision system. source: R. Cueto, J. Atencio, J. Gómez.
4. CONTEXT-BASED MODELING PROPOSAL
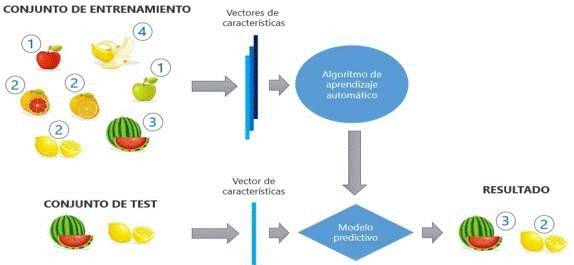
The watermelon crop is exposed to threats derived from pests and diseases, which can have a negative impact on both the production and quality of the fruits. Detecting these pests and diseases in their initial stages is of utmost importance, as it allows for the timely application of preventive and corrective measures. A possible effective solution to this challenge lies in the adoption of systems based on computer vision that, through image analysis, automatically identify pests and diseases present in watermelon plants. This innovation presents promising potential to enhance crop health management and improve decision making in the agricultural industry. See figure 2.
Fig. 2. Data interaction model. source: Machine Learning Model
The plan is to develop a computer vision system that takes a contextual modeling approach for pest and disease detection in watermelon fields. Within this context, context-based modeling refers to the system's ability to take into account the surrounding environment and the specific characteristics of watermelon plants while performing the identification and classification of these threats.Data acquisition: It is required to obtain images of watermelon plants in both healthy states and those affected by different pests and diseases. These images will constitute the training data set for the computer vision system.
Image conditioning: Before introducing images to the model, it is essential to apply a conditioning process to improve their quality and reduce noise. This could include actions such as correcting color balance, adjusting contrast, and removing unwanted backgrounds.
Feature Extraction: In order to facilitate the identification and categorization of pests and diseases, it is essential to obtain distinctive features from the images. This process may involve the application of computer vision algorithms, such as the Local Pattern Transform (LBP) or the Wavelet Transform, in order to capture salient patterns present in the images. These approaches allow us to recognize particular attributes that are specific to certain pests and diseases.
Contextual Modeling: The machine vision system must consider the context of the watermelon growing environment when carrying out identification and classification. This involves taking into account elements such as the shape of the leaves, the tone of the fruits, the detection of spots or damage, and any other relevant indicator to discern specific pests or diseases.
Model Training: It is essential to train a machine learning model and an advanced strategy to face this challenge involves the use of a Convolutional Neural Network (CNN), using the set of labeled images. The model must acquire the ability to identify distinctive patterns and traits related to various pests and diseases.
Verification and Tuning: Once trainings is completed, the model must undergo verification using a separate data set. It may be necessary to make adjustments to hyper parameters or modifications to the model to improve its efficiency and accuracy.
Commissioning and Implementation: Once the model has been verified and fine-tuned, it is possible to put it into operation in a computer vision system capable of processing images simultaneously. This could involve using cameras or sensors to capture images of watermelon plants in the field and transmit them to the processing system. See figure 3.
Fig. 3. Example interaction. source: R. Cueto, J. Atencio, J. Gómez.
Corresponde al registro de un usuario en la aplicación del sistema, vinculado a cada función dentro del sistema. La información de validación del sistema se preservará en caso de que aún no se haya inscrito. Adicionalmente, en nuestra demostración interactiva, tras cargar o adquirir imágenes, será feasible to visualize the diseases detected in the searched images. After uploading or taking photos, the analysis of the diseases that will occur in the plants is enabled.5. ARCHITECTURE
The application, identified as the Sandi app, includes three essential components for its operation (Graphical Abstract): At the user level, initially there is an interface layer or GUI developed using the FLUTTER© language in the Android Studio© environment. This layer enables the user to interact with the application installed on their mobile device. Secondly, the logical layer or control interface is presented, which covers the programming of the component classes. This section is developed using the VS Code environment (based on the FLUTTER© SDK) and uses an API linking library based on JAVASCRIPT, JAVA and C (Dart©). The third layer is known as the persistence layer, which is also configured on the server side and is related to data warehouse interface processing and transaction management. The integration of the database into the system is carried out by using the Google Firebase API, which is used for information storage. The primary actors of the system are the users (clients) who interact with the system through the navigation menus on each screen of the application. Table 2 details the modules that the user can access.Table 2. User modules. source: R. Cueto, J. Atencio, J. Gómez.
| WIDGETS | LOCAL | ONLINE |
|---|---|---|
| Registration | - | |
| User | - | |
| Upload Image | - | |
| Disease Search | - | |
| See Treatment | - | |
| Show Care | - | |
| View Report | - | |
| Filter Information | - | |
| Profile | - |
Since this project is a mobile application, its operation has been designed to run on the Android platform (version 4.4), which demonstrates greater compatibility with a wide range of mobile devices (smartphones) available on the market.
The system structure adopts a client-server approach, where clients interact with the interface, perform actions, update views, and load data. The architecture maintains the state of the application, manages requests to and from the server, and controls the presentation of information.
When an operation is performed on the application, such as verifying a user's access, the app sends an HTTP request (based on the DART® API) to a web server. This server contains data stored in a database, which is hosted on a web service for the purpose of offering online advice.
The web server is responsible for recording or updating information, responding to requests from client applications, assigning tasks to web services, managing data storage or extraction operations from the database, updating system tables, loading data into a server or run specific queries. Back to the mobile application, it processes and presents the information in JSON© format. The structure of our system is visualized in the Graphical Abstract that has been prepared.
6. MOBILE APP TESTING AND EVALUATION FRAMEWORK
When opening the application, an-interface is displayed where the user can log in, followed by a login form for those users who are already registered on the platform, allowing them to continue from that stage otherwise. As shown in Figure 5, the initial screen of the application is shown. This screen validates that the user's login attempt is invalid, triggering an-error message and blocking access to the user's options menu. See figure 4 and 5.
Fig. 4. Session begins.
Evaluation of the User Registration Process: Figure 6 illustrates the interface corresponding to the user registration procedure. In this evaluation, the user registration process is carried out, the images are organized following the established flow and, ultimately, the resulting screen is presented
Figure 5. User register. source: R. Cueto, J. Atencio, J. Gómez.
Watermelon (Citruulus vulgaris), a plant that belongs to the cucurbit family, has its origins in the Kalahari Desert in Africa, where it is still found in its wild form. The first signs of its cultivation date back to approximately 3000 BC. and were recorded in Egypt, from where its cultivation expanded to different regions in the Mediterranean area. With respect to this research focused on diseases and pests in watermelon crops, it is relevant to highlight that there are various varieties of this crop, each with its own specific diseases and pests, as mentioned (J. M. G. Recinos, Rendimiento de híbridos de sandía tipo personal; valle del Motagua, Zacapa., Zacapa, 2015).One of the main challenges facing agriculture today is the need to achieve high yields without depleting natural resources. To ensure sustainability in agriculture, it must be productive from an economic point of view, but must also consider the preservation of natural resources and environmental integrity at local, regional and global levels. Furthermore, it is crucial to take social and cultural diversity into account when exploring effective alternatives, as suggests. Watermelon, being a highly delicate fruit, is susceptible to pests and diseases that affect specific parts of the plant, particularly the leaves. In this context, relevant information about the pest detection process is provided. According to (Ramírez Escalante, Boris. Procesamiento Digital de Imágenes, 2006), in an-interview, farmers often identify pests intuitively by going to the field and carefully observing the crops. Although experience may guide your observations, it is common for the effects of pests or diseases to be consistent, such as the yellowing of leaves that is often associated with pests such as aphid and diseases such as fusarium. However, less experienced farmers could make mistakes and resort to incorrect use of agrochemicals.
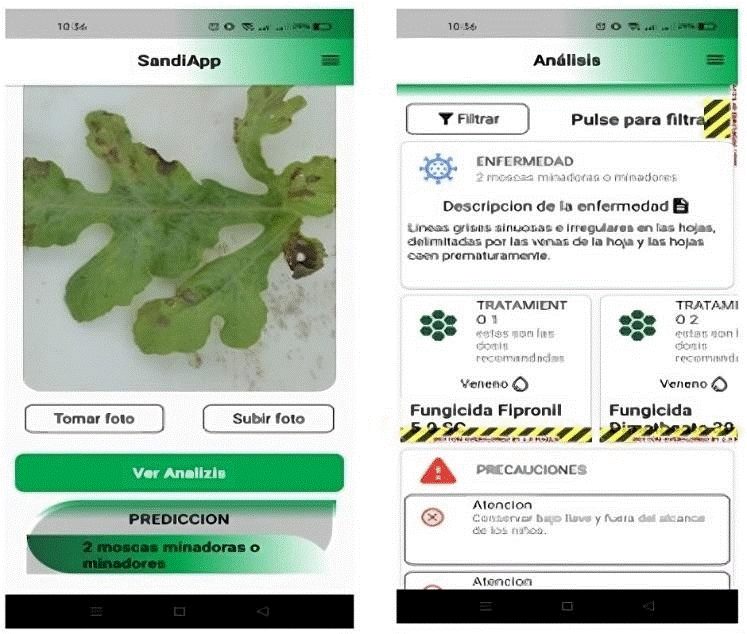
Additionally, according to (J. M. G. Recinos, Rendimiento de híbridos de sandía tipo personal; valle del Motagua, Zacapa., Zacapa, 2015), artificial intelligence refers to the creation of elements that exhibit intelligent behaviors, which include the ability to learn, adapt to changing contexts, manifest creativity and other abilities, and all this in combination with ability to perform such functions. This field is exceptionally diverse, spanning areas as broad as neuroscience, psychology, information technology, cognitive science, physics, mathematics, and much more. Furthermore, a variety of perceptions and actions can be obtained and generated through physical and mechanical sensors in devices, as well as through electrical or light signals in computer systems. These processes are performed through input and output modules in programs and their software environment. Examples of these procedures range from monitoring systems and scheduling automation to response diagnostics, customer interaction, handwriting recognition, voice identification, and pattern detection. See figure 6. Artificial intelligence is already widely implemented in various sectors, such as economics, medicine, engineering and the armed forces.
Likewise, it is applied in numerous software applications, video games and strategies, such as computerized chess and other electronic devices. By exhaustive examination of the literature.
Figure 6. Prediction and its respective analysis. source: R. Cueto, J. Atencio, J. Gómez.
6.1 Procedures in which we enter the training of the data obtained.
6.1.1 Convert lists to numpy arrays
X = np.array(imagenes)y = np.array(etiquetas)
Here, the lists images and labels are converted into NumPy arrays X and y, respectively. This is required to work with the functions and methods provided by the NumPy library and SciKit-Learn.
6.1.2 Check dimensions of images
print("Dimensiones originales de las imágenes: ", X.shape[1:])This line prints the original dimensions of the images. X.shape returns a tuple containing the dimensions of the array.
6.1.3 Flatten images
X = X.reshape(X.shape[0], -1)Here, images are "flattened" using reshape. This means that they transform from two-dimensional arrays to one-dimensional arrays. This is common in image processing so that each image is converted into a one-dimensional vector of pixels.
Split the training and testing data set: X_entrenamiento, X_prueba, y_entrenamiento, y_prueba = train_test_split(X, y, test_size=0.3, random_state=1)
The data set is split into training (X_training, y_training) and test sets (X_testing, y_testing) using the train_test_split function of SciKit-Learn.
30% of the data set is used as a test set (test_size=0.3) and a random seed (random_state=1) is set to ensure reproducibility.
6.1.4 Create the decision tree classifier
arbol = DecisionTreeClassifier()A decision tree classifier object is created using SciKit-Learn's DecisionTreeClassifier class.
6.1.5 Train the decision tree:
arbol.fit(X_entrenamiento, y_entrenamiento)The decision tree is trained on the training set (X_training, y_training) using the fit method. This means that the model will learn to make decisions based on the features of the images to predict the labels.
6.1.6 Predict test labels
y_prediccion = arbol.predict(X_prueba)The decision tree is used to make predictions on the test set (X_test) using the predict method.
6.1.7 Evaluate model accuracy
precision = metrics.accuracy_score(y_prueba, y_prediccion)print("Precisión: ", precision)
Finally, the accuracy of the model is calculated by comparing the predicted labels (y_prediction) with the actual labels of the test set (y_test) using the accuracy_score function of SciKit-Learn. The accuracy is printed on the screen.
In summary, this code performs a complete process of training and evaluating a decision tree-based classification model using image and label datasets. The accuracy of the model is calculated and displayed as a result.
We observe the results of the decision tree algorithm.
Result: decision tree 19002<=0.45
So, in summary, what this code does is take the trained decision tree (tree), generate a text representation of that tree, and then print it to the console. This text representation provides information about how the tree is split at each node, what features are used at each split, and what the decision criteria are at each node. This is useful for understanding the internal logic of the decision tree and how it makes decisions based on input features. Feature names are also included for better understanding (Gómez et al., 2023; Oviedo et al.,2019).
Figure 7. Confusion matrix. source: R. Cueto, J. Atencio, J. Gómez
A display figure with a size of 8x6 inches is created using plt.figure(figsize=(8, 6)).sns.heatmap from the Seaborn library is used to plot the confusion matrix as a heat map. confusion_matrix is the confusion matrix calculated in the previous step, and annot=True indicates that the values within the heatmap cells should be displayed.
fmt="d" specifies the format of values inside cells (integers).cmap="Blues" establece el esquema de colores a utilizar en el mapa de calor. En este caso, se usa el esquema de colores "Blues" que va desde tonos más claros a más oscuros para representar los valores. cbar=False prevents a color bar from being displayed on the side of the heat map.
Labels are then added to the x and y axes to indicate the true and predicted labels, and a title is added to the figure.
Finally, the visualization is shown with plt.show(). In summary, this code calculates the confusion matrix to evaluate the performance of the classification model and creates a visualization of the confusion matrix in the form of a heat map for easy interpretation of how the model is right or wrong in its predictions.
6.2 Neural network model and its epochs
This code concerns building, training, and evaluating a neural network model using the Keras library (which is part of TensorFlow) in Python. Here is a step-by-step explanation:A Sequential Neural Network model is created which is a linear stack of layers.
The first layer is a Dense layer with 64 units and ReLU activation ('relu'). This layer has an input with the same shape as the input characteristics of the data (input_shape=(X_training.shape[1],)).
The second layer is another dense layer with a single unit and sigmoid activation ('sigmoid'). This layer is commonly used in binary classification problems to obtain a probability between 0 and 1 as output.
The model is compiled using the 'adam' optimizer, which is a widely used optimizer in training neural networks.
The loss function is specified as 'binary_crossentropy', which suggests that the problem is binary classification. This loss function measures how well the model fits the true labels.
It is also specified that we want to track the accuracy metric during training.
The model is trained using the training set (X_training and y_training) for a specific number of epochs (10 in this case) using the fit method.
The parameter batch_size=32 indicates that a batch size of 32 samples will be used at a time during training. This helps speed up the training process and can improve training stability.
Se evalúa el modelo utilizando el conjunto de prueba (X_prueba e y_prueba) utilizando el método evaluate.
El resultado de la evaluación se almacena en la variable evaluacion, que contiene la pérdida y la precisión (accuracy) del modelo.
Finalmente, se imprime la precisión del modelo en el conjunto de prueba.
The importance of this code is that it shows how to build, train and evaluate a neural network model to solve a binary classification problem. Neural networks are a powerful deep learning technique and are used in a variety of applications, from image processing to natural language processing
and more. Understanding how to design and train neural network models is critical for advanced data science and machine learning applications. The accuracy of the model on the test set provides information about its performance on unseen data and can guide decisions about its usefulness in real applications.
6.3 Decision tree
Interpretability: Decision trees are highly interpretable. You can visualize the tree and easily understand how decisions are made at each node. This is useful to explain and justify model decisions.Performance on tabular data and simple features: Decision trees perform well on tabular data with simple features. They are good for problems where the relationships between features and labels are clear and non-linear.
Sensitivity to noisy data: Decision trees can be sensitive to noisy data or outliers. They can be overfitted if not properly controlled.
Ease of training and prediction: Decision trees are relatively fast to train and predict compared to more complex models such as neural networks.
6.4 Neural Network
Representation ability: Neural networks have strong representation ability and can learn complex relationships between features and labels. They are suitable for a wide range of machine learning problems, including computer vision problems, natural language processing, and more. Nonlinearity: Neural networks can model nonlinear relationships between features and labels more effectively than decision trees.Requires more data and resources: Neural networks typically require larger data sets and more computational resources to train properly. They may also require more hyper parameter adjustments.
Less interpretability: Neural networks tend to be less interpretable than decision trees. The internal structure of a neural network can be complex and difficult to understand.
6.5 Comparison
If the problem is relatively simple and the data is tabular with linear or simple relationships between features and labels, a decision tree might be an appropriate choice due to its interpretability and efficiency.If the problem is more complex and requires capturing non-linear relationships or sophisticated patterns in the data, a neural network might be more appropriate. However, this could require more data and computational resources.
In general, it is good practice to test various types of models, including decision trees and neural networks, and compare their results using evaluation metrics such as precision, recall, and F1-score on an independent test set. This will help you determine which model best suits your specific problem. You can also consider interpretability and available resources when making your decision.
7. CONCLUSIONS AND FUTURE WORK
After carrying out the evaluations in the development process of this project, the following can be concluded:Through the implementation of the computer vision system, farmers have experienced an increase in their understanding of pests and diseases that affect watermelon crops. According to the results of the survey, it can be deduced that 81.2% of respondents have stated that the information provided has enriched their level of knowledge, meeting their expectations by providing concise and complete details. On the other hand, before the introduction of the software, only 26.5% of farmers had mentioned having basic and secondary levels of information. Evidently, the level of digitalization has seen considerable improvement.
Additionally, the inclusion of machine vision systems has significantly increased the proportion of farmers who now have a better understanding of recommended agricultural chemicals. According to the survey, 82.6% of the population currently claims that the information provided has contributed to raising their level of awareness. In contrast, before the implementation of the software, only 5.8% of farmers had expressed having a moderate level of information. Again, it can be inferred that the system has managed to meet its stated objectives.
In summary, the development of an artificial vision system with the purpose of identifying pests and diseases in watermelon cultivation constitutes an innovative and effective solution to the challenges faced by agriculture. This solution combines advanced technologies such as image processing and machine learning to offer accurate and reliable tools that support farmers in the timely detection and management of pests and diseases that harm watermelon crops. Through advanced cameras and algorithms, machine vision technology has the ability to analyze images of watermelon plants for signs and symptoms of pests and diseases. This allows for rapid and accurate identification, facilitating informed decision-making and the implementation of targeted control measures. Additionally, the system offers various advantages for farmers. Perform thorough and agile inspections over large crop areas, reducing the need for manual inspections and saving time and resources. It also provides objective evaluations and uniforms, reduces human errors and allows the adoption of early preventive measures.
The introduction of an artificial vision system designed to recognize pests and diseases in watermelon cultivation presents great potential to increase the productivity and profitability of farmers, while minimizing the environmental impact by reducing the use of pesticides and other chemicals. This approach is emerging as a highly promising tool in the field of precision agriculture, paving the way for future advances in crop control and management.
In summary, the integration of the artificial vision system in watermelon production offers an extremely effective and efficient solution for the early detection and control of pests and diseases. Its ability to improve production efficiency, reduce costs and mitigate environmental impact makes it an invaluable resource for farmers facing crop health challenges. Below are some recommendations to further strengthen the development of artificial vision systems with regard to the identification of pests and diseases in watermelon cultivation:
Increase accuracy: Continuing to improve algorithms aimed at detecting and recognizing pests is crucial. This involves collecting a variety of high-resolution images to train the machine learning models, as well as conducting constant testing and validation to raise the accuracy and reliability of the system.
Expand the database: In order to optimize the effectiveness of the system, it is essential to establish and maintain an updated and extensive database that covers images of various pests, diseases and situations that affect watermelon cultivation. As this database grows in size and diversity, the system's ability to recognize and categorize a variety of challenges that may arise in crops will be greatly improved.
Integrate multiple technologies: Machine vision can be enriched with other technologies, such as temperature, humidity or soil quality sensors, to obtain a complete understanding of the status of watermelon crops. The combination of these technologies can provide a comprehensive assessment of plant health and enable more accurate and timely decisions in crop management. Develop an intuitive user interface: For farmers to get the most out of the machine vision system, it is essential to design a user interface that is easy to understand and use. This interface allows them to seamlessly interact with the system, access reports and results, and understand the recommendations and suggested actions.
Adaptability to different environments and conditions: Since watermelon crops can grow in various contexts and conditions.
As we consider geographic and environmental factors, it is important that machine vision systems are adaptable to a wide range of climates, watermelon types, and growing methods. This involves addressing differences in pest and disease incidence depending on specific conditions, ensuring the system is resilient and accurate in various scenarios. It is also crucial to encourage constant collaboration and receive continuous feedback.
Collaboration between researchers, farmers and agricultural technology experts becomes an essential component to ensure the constant evolution of this system. The contributions of end users are invaluable to identify areas of improvement and address the individual needs of producers regarding the detection and control of pests and diseases in watermelon crops.
The implementation of these recommendations can result in increasingly efficient and valuable artificial vision systems for the identification and management of pests and diseases in watermelon crops. This, in turn, will contribute to more productive, sustainable and profitable agriculture.
ACKNOWLEDGMENT
Thanks to the University of Córdoba for financing this research project according to the internal call with project code FI-05-19. We also thank the SOCRATES research group of the Systems Engineering and Telecommunications program for supporting the development of this project.REFERENCES
Pardo G., A. y Díaz R., J. L. (2004). Aplicaciones de los convertidores de frecuencia, Estrategias PWM, Editorial Java E. U., Colombia.Ogata, K. (2004). Ingeniería de Control Moderna, Prentice Hall, Cuarta edición, Madrid.
Clymer, J. R. (1992). “Discrete Event Fuzzy Airport Control”. IEEE Trans. On Systems, Man, and Cybernetics, Vol. 22, No. 2.
Gómez-Camperos, J.A., Jaramillo, H.Y., & Guerrero-Gómez, G. (2021). Técnicas de procesamiento digital de imágenes para detección de plagas y enfermedades en cultivos: una revisión. INGENIERÍA Y COMPETITIVIDAD.
Martínez-Corral, L., Martínez-Rubín, E., Flores- García, F., Castellanos, G.C., Juarez, A.L., & López, M. (2009). Desarrollo de una base de datos para caracterización de alfalfa (Medicago sativa L.) en un sistema de visión artificial.
Santa María Pinedo, J.C., Ríos López, C.A., Rodríguez Grández, C., & García Estrella, C.W. (2021). Reconocimiento de patrones de imágenes a través de un sistema de visión artificial en MATLAB. Revista Científica de Sistemas e Informática.
Malpartida, S., & Ángel, E.T. (2011). Sistema de visión artificial para el reconocimiento y manipulación de objetos utilizando un brazo robot.
Vargas, O.L., & Perrez, Á.A. (2019). Implementación de un Sistema de Visión Artificial para la clasificación de naranja producida en el departamento del Quindío.
León León, R.A., Jara, B.J., Cruz Saavedra, R., Terrones Julcamoro, K., Torres Verastegui, A., & Aponte de la Cruz, M.A. (2020). DESARROLLO DE SISTEMA DE VISIÓN ARTIFICIAL PARA CONTROL DE CALIDAD DE BOTELLAS EN LA EMPRESA CARTAVIO RUM COMPANY. Ingeniería Investigación y Desarrollo.
Ramírez Escalante, Boris. Procesamiento Digital de Imágenes [en línea], Verona, [citado agosto, 2006].
J. M. G. Recinos, Rendimiento de híbridos de sandía tipo personal; valle del Motagua, Zacapa., Zacapa, 2015.
Bautista, R.A., Constante, P., Gordon, A., & Mendoza, D. (2019). Diseño e implementación de un sistema de visión artificial para análisis de datos NDVI en imágenes espectrales de cultivos de brócoli obtenidos mediante una aeronave pilotada remotamente.
Prócel, P.N., & Garcés, A.M. (2015). Diseño e implementación de un sistema de visión artificial para clasificación de al menos tres tipos de frutas.
Yandún Velasteguí, M.A. (2020). Detección de enfermedades en cultivos de Papa usando procesamiento de imágenes.
Martínez, F.H., Montiel, H., & Martínez, F. (2022). A Machine Learning Model for the Diagnosis of Coffee Diseases. International Journal of Advanced Computer Science and Applications.
Ortega, B.R., Biswal, R.R., & Sánchez-Delacruz, E. (2019). Detección de enfermedades en el sector agrícola utilizando Inteligencia Artificial. Res. Comput. Sci., 148, 419-427.
Zapata, V., & Alejandro, J.R. (2019). Diseño y desarrollo de un sistema prototipo de diagnóstico de afecciones en plantas de cítricos utilizando procesamiento de imágenes y aprendizaje profundo.
Pillajo, M.A., Pillajo, M.A., & Cabascango, A.S. (2019). Diagnóstico inteligente de enfermedades y plagas en plantas ornamentales.
Narciso Horna, W.A., & Manzano Ramos, E.A. (2021). Sistema de visión artificial basado en redes neuronales convolucionales para la selección de arándanos según estándares de exportación. Campus.
Huaccha, E.D. (2018). Desarrollo de un sistema de visión artificial para realizar una clasificación uniforme de limones.
Bautista, R.A., Constante, P., Gordon, A., & Mendoza, D. (2019). Diseño e implementación de un sistema de visión artificial para análisis de datos NDVI en imágenes espectrales de cultivos de brócoli obtenidos mediante una aeronave pilotada remotamente. Infociencia.
Tinajero, J., Acosta, L.A., Chango, E.F., & Moyon, J.F. (2020). Sistema de visión artificial para clasificación de latas de pintura por color considerando el espacio de color RGB.
Salazar, P., Ortiz, S., Hernandez, T.H., & Bermeo, N.V. (2016). Artificial Vision System Using Mobile Devices for Detection of Fusarium Fungus in Corn. Res. Comput. Sci., 121, 95-104.
hyar, B.S., & Birajdar, G.K. (2017). Computer vision based approach to detect rice leaf diseases using texture and color descriptors. 2017 International Conference on Inventive Computing and Informatics (ICICI), 1074-1078.
Yasir, R., Rahman, M.A., & Ahmed, N. (2014). Dermatological disease detection using image processing and artificial neural network. 8th International Conference on Electrical and Computer Engineering, 687-690.
P. P. Garcia Garcia, Reconocimiento de imagenes utilizando redes neuronales artificiales, Madrid, España, 2013.
Orduz, J. O., León, G. A., Chacón Díaz, A., Linares, V. M., & Rey, C. A. (2000). El cultivo de la sandía o patilla (Citrullus lanatus) en el departamento del Meta (No. Doc. 21998) CO- BAC, Bogotá.
González Sánchez, H. A. (1999). Impacto ambiental de la labranza mecánica convencional. Departamento de Ciencias Agropecuarias.
R. Jorge, Introducción a los sistemas de visión artificial, Madrid, España, 2011.
CHAVEZ, Procesamiento de imágenes [en linea], Puebla, Universidad de las Américas puebla [citado en 6 de Julio de 2015].
MATWORKS, Detección de bordes [en línea], [citado en 6 de octubre de 2015].
A. Marin Poatoni, Desarrollo de prototipo de aplicacion (APP), para dispositivos móviles basados en el sistema IOS, para el reconocimiento de objetos"Hojas" en imagenes, Motecillo, Mexico, 2014.
H. T. T., L. V. G. Bay, «Speeded-Up Robust,» EE. UU, 2006.
Gomez, J. G., Hernandez, V., & Ramirez- Gonzalez, G. (2023). Traffic classification in IP networks through Machine Learning techniques in final systems. IEEE Access.
Oviedo, B., Zambrano-Vega, C., & Gómez, J. (2019). Clasificador Bayesiano Simple aplicado al aprendizaje. Revista Ibérica de Sistemas e Tecnologias de Informação, 18, 74-85.